结果
程序简单跑了一下,发现一个 11 阶的结果,具体展示如下(为了方便我肉眼校验,是矩阵叉乘形式输出的,还没有转换成拉丁阵)。不保证上述结果是最优的,且有一点争议,一个是丁 + 口 = 可是否算,另一个是心字底和竖心旁是当做一样的(见怜、恭),还有提手旁和手字底当做一样(见拎、拲)。这几个问题还不太好修正,下面会说一下具体细节。
更新:感谢 @ 昊天辽远任翱翔 的建议:”烡可以换成烘,拲可以换成拱,恭可以换成㤨,可可以换成叮,集可以换成椎,坌可以换成坋"。这边也跟我实现的处理有关,替换以后合理很多。类似的, @一个普通人 提到“惌”可以改成“惋”。我自己也发现一个,“忿”可以改成“㤋”。


两个结果的文字版本也贴出来,代码输出的原始结果。
令 共 隹 枼 番 斤 分 宛 亢 需 丁
口 呤 哄 唯 喋 噃 听 吩 啘 吭 嚅 叮
虫 蛉 蛬 蜼 蝶 蟠 蚚 蚡 蜿 蚢 蠕 虰
火 炩 烡 焳 煠 燔 炘 炃 焥 炕 燸 灯
石 砱 硔 碓 碟 磻 斫 砏 碗 砊 礝 矴
水 泠 洪 淮 渫 潘 沂 汾 涴 沆 濡 汀
木 柃 栱 椎 楪 橎 析 枌 椀 杭 檽 朾
土 坽 垬 堆 堞 墦 圻 坌 埦 坑 壖 圢
女 姈 娂 婎 媟 嬏 妡 妢 婉 妔 嬬 奵
手 拎 拲 推 揲 播 折 扮 捥 抗 擩 打
心 怜 㤨 惟 惵 憣 忻 忿 惌 忼 懦 忊
人 伶 供 倠 偞 僠 伒 份 倇 伉 儒 仃
手工修正后的结果
令 共 隹 枼 番 斤 分 宛 亢 需 丁
口 呤 哄 唯 喋 噃 听 吩 啘 吭 嚅 叮
虫 蛉 蛬 蜼 蝶 蟠 蚚 蚡 蜿 蚢 蠕 虰
火 炩 烘 焳 煠 燔 炘 炃 焥 炕 燸 灯
石 砱 硔 碓 碟 磻 斫 砏 碗 砊 礝 矴
水 泠 洪 淮 渫 潘 沂 汾 涴 沆 濡 汀
木 柃 栱 集 楪 橎 析 枌 椀 杭 檽 朾
土 坽 垬 堆 堞 墦 圻 坋 埦 坑 壖 圢
女 姈 娂 婎 媟 嬏 妡 妢 婉 妔 嬬 奵
手 拎 拱 推 揲 播 折 扮 捥 抗 擩 打
心 怜 恭 惟 惵 憣 忻 㤋 惋 忼 懦 忊
人 伶 供 倠 偞 僠 伒 份 倇 伉 儒 仃
汉字处理
代码实现的前提是要能够用办法把汉字和它的偏旁部首对应起来,在 Github 上找到了一个有用的素材,https://github.com/howl-anderson/hanzi_chaizi,通过它找到了《汉语拆字字典》(GitHub - kfcd/chaizi: 漢語拆字字典),基于这份数据(简体版)进行了计算,字典里包含了 19751 个汉字的数据(理论上把繁体版加进来,还能包括更多汉字)。注意有以下几点数据处理:
- 一个字可以拆成大于两个部分,比如“旅” -> ["方", "丿", "一", "氏"],还有“旁” -> ["亠", "丷", "冖", "方"]。这一类没太想好咋处理,读数据的时候直接跳过了,只读取了能拆成两个部分的字。
- 一个字可能有多个拆法,主要情况是有的偏旁部首有多种写法,比如“芦” -> ["草", "户"], ["艸", "户"], ["艹", "户"],此处就是草字头有多种展现形式。观察了一下字典里面所有草字头的多种表达顺序是一致的,所以为了控制问题规模,每个字只读取了第一种拆法。不过有一点尴尬的就是草字拆字就成了,"草" -> ["草", "早"]。还有就是会出现上面说的心字底和竖心旁是当做一样的,还有提手旁和手字底当做一样的情况。
- 因为“草”字这个观察,以及有一些其他奇怪的汉字字符(偏旁部首本尊),又加了一个规则,从汉字集合中删除出现在偏旁部首中的部分。
- 存在两个偏旁部首可以组成多个汉字的,我只存了一个。具体程序实现时候是存了最后一个出现的汉字,导致有些偏旁部首组合没有输出更常见的字。
经过上面的这些筛选,大约有 2100 的汉字和对应的偏旁部首筛选出来进入了模型计算。这部分有没有更恰当的处理办法,欢迎大家提建议。
数学模型
定义集合
表示所有拆出来的偏旁部首,定义集合
表示所有可以组合在一起的两个偏旁部首,定义集合
为所有可以组合出来的汉字。由于一个汉字可能存在多种拆字方法,所以定义集合
表示所有可以组合成汉字
的偏旁部首组合。
上述定义其实是以偏旁部首为节点构成了一张图,原题目等价于在图上找出两组数量相等的节点,形成一个最大的完全二部图(complete bipartite graph),存在一个额外的约束,是同一个汉字的偏旁部首组合只能选一个。我们可以建立整数规划模型求解。
定义决策变量:
对应的数学模型如下:
目标是最大化阶数。前两组约束保证了二部图选出来的点数和阶数相等。接下来三组约束保证了只有
时,
。之后四组约束保证了选出来的二部图是完整的。最后一个约束算是个有效不等式,一个偏旁部首不会被二部图的两组节点同时选中。上述模型还是很弱的,求解时可以看到 bound 非常糟糕,导致求解时间较长,后续可以持续优化。
更新结果包含金木水火土版本
@六翼 评论说偏旁里缺了个“金”难受,本来想重新跑个锁定“金木水火土”的版本,不过 @浅夏青柠 和 @大漠孤盐 都提到,现有的横排这几个字都是可以加金字旁的。所以就手工加一行更新一下结果吧(顺便把顺序调整了)。注意此时是 12 * 11 的结果,如果横排还能再加一个字进去,我们就能构造出一个 12 阶的结果了。

包含斜玉旁版本
@一直是太史子义慈 问到为啥没有斜玉旁,于是固定住必须选“玉”算了一把,同样可以生成 11 阶的结果,具体如下。

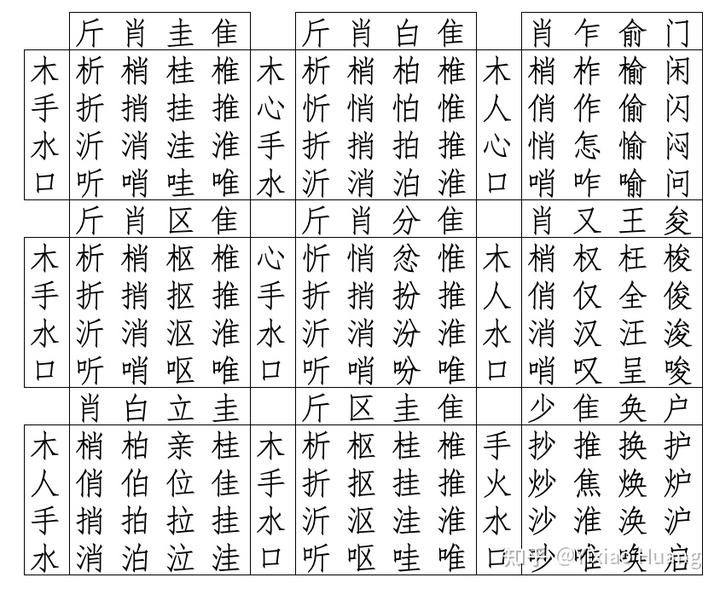
限定 3500 常用字版本
@大老李@kwasglag 提到限定在 3500 个常用字范围内,看一下最高阶是多少。算出来最高是 4 阶,有很多很多种组合方式,我生成了九个放在下面了(注意还是有一些有争议的字,比如火字组成的焦字,还有启字)。