为什么我国的概率与统计学教科书里不怎么讲幂律分布?

这个问题简直是直接撞到了我的枪口上。
就在上周,我正和出版社的编辑还在讨价还价。我目前正在写一本面向自学者的概率论教材,原稿写得太嗨(很多直白的讲解),不知不觉飙到了 600 多页。
编辑说:“书太厚了,定价压不下来,读者可能不买账。第 7 章这些像‘幂律分布’的扩展内容,考研大纲里也没有,要不砍掉吧?或者我们做成二维码,印在书页角落,想看的读者自己扫码看电子版?”
听到这个提议,我有点纠结。一方面我理解出版的商业现实考虑;但另一方面,把统治了现实世界财富、流量与大模型底层逻辑的分布规律,委屈成一个“扫码扩展阅读”的边缘角色,让我觉得有点可惜。
回到题主的问题:为什么中国教材不教幂律分布?
因为现有的概率论教学体系,是建构在“正态分布”和“中心极限定理”的地基上的。它假设世界是“独立同分布”的(扔硬币,你扔你的,我扔我的)。而幂律分布的底层逻辑是“相互关联、正反馈”(滚雪球,富者愈富)。这种复杂系统的规律,为了保持基础教材体系的“整洁”,往往被划到了系统科学或更深层的学科里。
在现有的教学体系下,我们的大学教材本质上是考试大纲的附属品,而不是教你认识真实世界的说明书。
既然实体书里它大概率只能变成一个二维码了,我就把这部分“超纲原稿”直接发在这里。
章节名:赢家通吃的幂律分布
此前我们接触的均匀分布、指数分布和正态分布,都有一个共同点:它们共同构建了一个温和的“平均王国”。大家都差不多,没有特别穷的,也没有特别富的。
但现在,我们要把这个温和的面具撕下来了。在这里,没有所谓的“典型值”,极端事件不再罕见,而是一种常态。在这里,“第一名”的收益,可能比第二名到第一百名加起来还要多。
这听起来并不陌生,我们生活的世界到处都是这种分布的影子:亿万富翁的财富、明星城市的规模、网络热搜的流量……要理解它们,我们需要一件新工具——幂律分布。
1. 从两个“为什么”说起
第一个“为什么”:假设一个房间里有 100 个人,他们的年收入大致服从正态分布,平均值是 10 万元。这时,世界首富走了进来。你猜,这个房间里的平均收入会变化多少?可能会翻倍?变成 20 万?还是 50 万?实际上,这个数字可能会变成数千万甚至上亿。一个极端个体的加入,彻底重塑了整个统计结果。在正态分布的世界里,这是不可想象的“黑天鹅”;但在幂律分布的世界里,这却是每天都在发生的寻常事。
第二个“为什么”:随便想一个英文单词,比如 “the”。你凭直觉觉得,它在所有英文文本中出现的频率大概是多少?实际上,“the”这个单词出现的频率高达 7% 左右。大约每 14 个词里就有一个。而排名第二的“of”,频率就骤降到 3.5% 左右。这和我们直觉里“词汇应该均匀分布”的想法相去甚远。
这两个现象指向同一个核心:在这类分布中,极大值出现的概率,没有想象中那么低。它的图形,有一个极其漫长的“尾巴”,向右方无限延伸。我们称之为——“长尾”或“肥尾”。
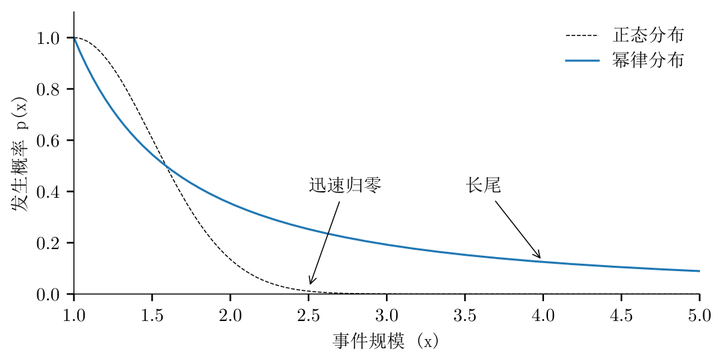
正如图 1 的直观对比,正态分布是一条钟形曲线,大部分数据集中在中间凸起处,两边的尾巴很快便匍匐在地,消失不见。幂律分布则是一条从高点开始,一路向右下方滑落的曲线。它下降的速度越来越慢,慢到那条尾巴似乎要贴着地面,延伸到视野的尽头。
2. 给“不平等”一个数学表达式
我们如何用数学语言来捕捉这种“漫长的尾巴”呢? 它的核心思想非常简洁:一个变量
超过某个很大数值
的概率,与
的某个负幂次成比例。
这个“
”是“正比于”的意思。
是一个大于 0 的常数,叫做“幂指数”或“尾指数”。这个公式就是幂律的灵魂。
翻译一下这句话:“数值超过
的可能性,随着
的增大,按照
的负
次方的速度衰减。”
关键在于这个“衰减的速度”。指数分布(如灯泡寿命)的衰减速度是指数级的快,就像雪崩一样。而幂律
呢?它的衰减速度是多项式级的,慢得多。
在这个世界里,要想消灭大数值,是非常非常困难的。正态分布消灭极端值,靠的是指数级的高压,像切菜一样利索;而幂律分布消灭极端值,只能靠多项式级的磨损,慢得让人绝望。
为了更精确,它的概率密度函数(PDF)通常写为:
(这里
)。这个关系直接造就了那条漫长的尾巴。
3. 最经典的两位“代言人”
在现实中,幂律有两位最著名的“代言人”。
第一位,是帕累托分布。 你大概率听过它的一个经验版本——80/20 法则。它描述财富、收入、公司规模等“资源不平等”现象。设
为最低门槛,财富超过
的人的比例就是
。你可以做一个思想实验:如果全球财富服从帕累托分布,世界首富的财富很可能比排名第十的富豪多一个数量级(10 倍)。这种“断层式”的差距,正态分布无法产生。
第二位,是齐普夫定律。 它描述系统中单元大小与其排名之间的反比关系:
当
时,排名第 1 位的规模约是第 2 位的 2 倍;第 10 位的规模约是第 100 位的 10 倍。这揭示了在存在竞争的系统中,一种“赢家通吃”或正反馈机制,往往会自发产生幂律结构。
4. 无标度性:幂律最深刻的“指纹”
幂律最精妙、也最反直觉的一个性质是——无标度性。
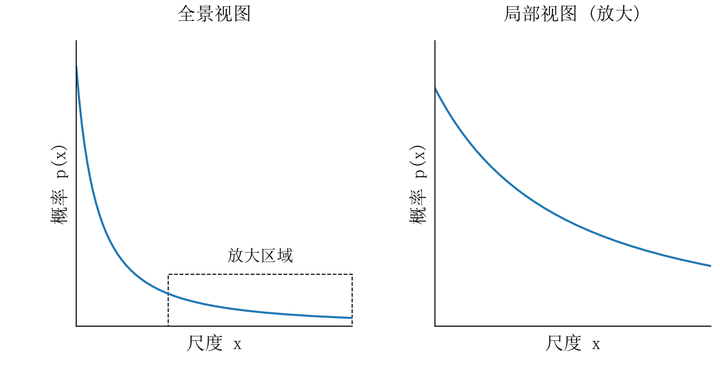
玩个“放大镜”游戏:假设你有一份美国城市人口数据,服从幂律分布。如果你只关注人口超过 50 万的大城市分析一次,再只关注超过 100 万的大城市分析一次。你会发现:这两次得到的分布形态,看起来几乎一模一样!
在这个世界里,你根本找不到一把合适的尺子。在正态分布里,“平均身高”就是那把尺子。但在财富的幂律分布里,你说身家 100 万算富吗?在 1000 万面前是穷光蛋。1000 万在 1 个亿面前又是穷光蛋。
正如图 2 所示,这种“大鱼吃小鱼,小鱼吃虾米”的结构,无论你把镜头拉到哪个层级,看起来完全一模一样。幂律分布,就是概率世界里的“分形”。
5. 对比与定位:在概率版图中找到它
学到这里,你脑子里可能同时转着好几个分布,有点打架。这很正常。接下来做几个对比,看看能不能帮助你更好理解。
第一场对比:幂律 vs. 指数分布(衰减的速度)
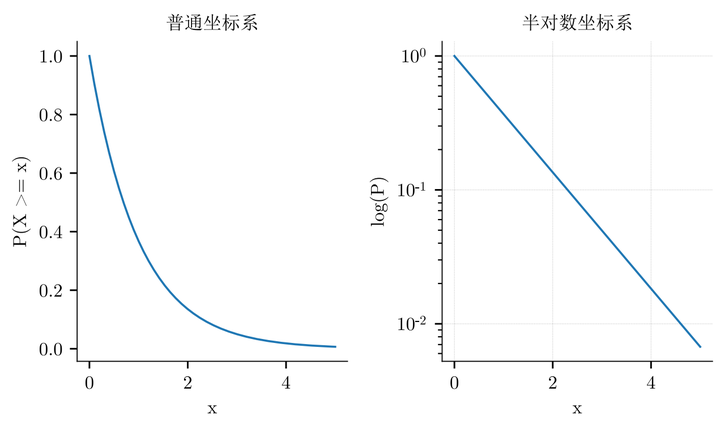
回忆一下,指数分布描述“无记忆”的等待,比如灯泡的寿命。它的核心是
。你注意看,变量
在指数上。这意味着它的衰减是指数级的,快如雪崩。在半对数坐标图(只有 y 轴取对数)上,它会画出一条直线(如图 3)。
而幂律呢?它的核心是
,变量
在底数上。它的衰减是多项式级的,慢如远去的驼铃。为了让它现出原形(变成直线),我们需要在双对数坐标图(x 轴和 y 轴都取对数)上看它(见图 4)。
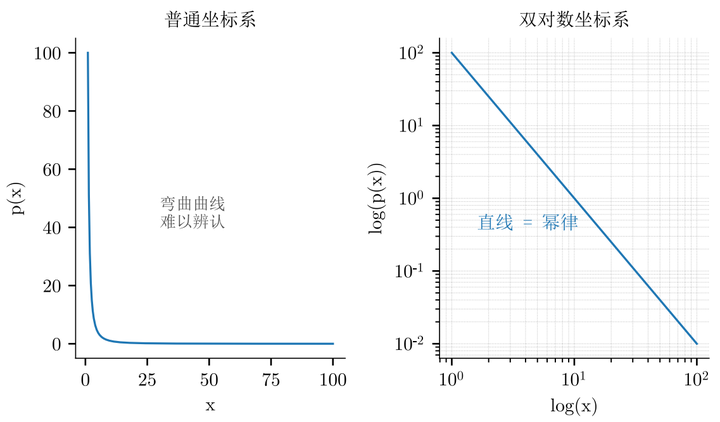
所以,区分秘诀是:看它在什么坐标系下成直线。这背后是衰减速度的本质差异:指数衰减把极端事件概率压得极低,而幂律则“宽容”地保留了这种可能。
第二场对比:幂律 vs. 正态分布(世界的规则) 现在,想想我们万能的“钟形曲线”。正态分布是“平均王国”的君主,它由大量独立、微小的因素相加而成(中心极限定理)。它崇尚“中庸”,把数据紧紧拉向均值,极端值是罕见的意外。
幂律分布则是“极端王国”的规则制定者。它通常由相互关联、具有正反馈的机制相乘(或类似累积)而成。“富者愈富”(偏好依附)就是最典型的规则。它热衷于制造垄断和巨头,在这里,极端事件不是意外,而是系统结构必然的产物。
一个是“独立相加”导向的平均与稳定,一个是“关联相乘”导向的集中与突变。理解你面对的问题属于哪个王国,是选择正确数学模型的第一步。人的身高属于前者,人的财富往往属于后者。
6.关键澄清:关于形式、离散与连续、截断
聊了这么多现象和性质,你可能对幂律分布本身还有些根本的疑问。
疑问一:它到底是离散分布还是连续分布? 答案是:两者皆有。幂律描述的是一种数学关系(比例于
),这种关系既可以刻画连续变量,也可以刻画离散变量。
- 连续型:如描述收入的帕累托分布,其概率密度函数
。
- 离散型:如描述词频的齐普夫定律,其概率质量函数
。 我们放在连续型分布这章讨论,是因为它与指数分布、对数正态分布等连续分布的对比更有启发意义。
疑问二:为什么我们只写“
”,不给个像正态分布那样漂亮的完整公式? 这是个好问题。我们写成
,而不是
,有两个现实原因:
- 必须的“起步价”:幂律在
时会爆炸到无穷大,无法归一化。因此,任何一个具体的幂律分布(如帕累托分布)都必须有一个最小值
,分布从这开始:
。这个
因问题而异(比如“城市”的最小规模),所以一个通用“标准式”反而不实用。
- 强制的“天花板”:同样因为现实世界有限,幂律的漫长尾巴不可能无限延伸。城市人口不能超过地球总人口,个人财富受限于全球经济总量。因此,更真实的模型往往是截断幂律,它在纯幂律基础上加了一个指数衰减项:
。当
远小于最大尺度
时,它像幂律;当
最小值
是定义数学模型的必需品,而最大值
是描述物理世界的必需品。这提醒我们,漂亮的幂律公式是一个抓住了核心机制的理想模型,而应用时,必须考虑现实世界的起止边界。
纯粹的幂律只存在于数学家的草稿纸上。现实世界总有物理极限。再大的雪球,滚到最后也会因为没有雪而停下(地球资源有限)。所以,真实的曲线往往是:中间一段极其符合幂律,但在最末端,会被现实的墙壁强行截断。
算法工程师彩蛋:大语言模型的长尾噩梦
最后说点我个人的本职工作。在我平时做的视觉语言模型(VLM)或者大语言模型(LLM)的训练时,最头疼的往往不是显卡算力,而是你刚刚学到的幂律分布(齐普夫定律)。
在人类语言和视觉特征中,极少数的模式占据了绝大多数流量,而绝大多数罕见模式只出现寥寥几次。这对 AI 来说是灾难性的样本不平衡——模型对高频数据“过拟合”,对长尾数据却因为没见过几次而“学不会”。
为了不让 AI 变成“文盲”,业界被迫发明了 Subword(子词)分词技术(如 BPE 算法),强行把生僻的长尾词切碎成高频的词根。今天最先进的 AI 架构,其实有很多底层逻辑就是被这种数学分布逼出来的。
动手实验:财富的乘法游戏
为了验证这不是数学家的空想,我为这本书配了一段无依赖的纯 Python 仿真代码。
在这个代码里,我们模拟一个“乘法游戏”(比如投资回报率)。每个人每一轮随机赚或亏 10%,并设定一个最低破产底线。你可以亲自跑一下,看看贫富分化是如何在双对数坐标下,无可阻挡地排成一条冰冷的直线的。
"""
文件名: wealth_distribution_simulation.py
功能: 模拟“乘法增长”与“贫困底线”如何共同制造出贫富悬殊的幂律分布。
【这是什么?】
这段代码演示了一个残酷的社会实验:
如果是“加法游戏”(每人每天随机赚 / 赔 1 块钱),财富会服从正态分布(大家差不多)。
但如果是“乘法游戏”(每人每天随机赚 / 赔 10%),且每个人都有最低生存底线,
最终就会诞生“幂律分布”:绝大多数人挣扎在底线附近,而极少数人掌握绝大部分财富。
【怎么用?】
直接运行即可。程序会弹出两个窗口:
1. 普通坐标图:你会看到一个巨大的“L”型,这就是贫富分化的直观样子。
2. 双对数坐标图:你会看到数据点神奇地排成了一条直线,这是幂律分布的铁证。
"""
import numpy as np
import matplotlib.pyplot as plt
# --- 可调整参数配置区 (你可以随意修改这些数字来观察世界) ---
# 1. 模拟的人数 (建议 1000 - 10000)
NUM_PEOPLE = 5000
# 2. 初始财富值 (也是贫困底线,跌破此线会触发“低保”或被新移民替代)
MIN_WEALTH = 10.0
# 3. 模拟的轮数 (时间越久,贫富分化越明显)
STEPS = 5000
# 4. 每一轮的波动幅度 (0.1 代表 10% 的盈亏)
VOLATILITY = 0.1
# ---------------------------------------------------------
def run_simulation():
# 初始化:所有人最开始都只有最低财富
wealth = np.full(NUM_PEOPLE, MIN_WEALTH)
print(f"正在模拟 {NUM_PEOPLE} 个人的财富演化,请稍候...")
for t in range(STEPS):
# --- 核心数学逻辑 1:乘法增长 (Multiplicative Process) ---
# 现实中的财富不是线性累加的,而是按比例增值的(如投资回报、复利)。
# 这里模拟每人每轮随机 盈 / 亏 VOLATILITY 的比例。
# np.random.uniform(-1, 1) 生成 -1 到 1 之间的随机数
fluctuation = 1 + VOLATILITY * np.random.uniform(-1, 1, NUM_PEOPLE)
wealth = wealth * fluctuation
# --- 核心数学逻辑 2:反射壁 (Reflective Barrier) ---
# 对应现实中的“生存底线”或“新入场的穷人”。
# 如果没有这个底线,乘法过程最终会变成对数正态分布。
# 加上这个底线后,数学上证明了它会收敛为幂律分布 (Kesten Process)。
wealth[wealth < MIN_WEALTH] = MIN_WEALTH
return wealth
def plot_results(wealth):
# 设置绘图风格
plt.style.use('ggplot')
# 尝试设置中文字体(为了让你的图表显示中文,这里做了兼容性处理)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
# 创建两个子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# --- 图 1:普通坐标下的直方图 ---
# 这是我们肉眼看到的“真实世界”:极度不平等
ax1.hist(wealth, bins=50, color='#3498db', alpha=0.8, edgecolor='black')
ax1.set_title("图 1:普通视角(贫富悬殊)")
ax1.set_xlabel("财富金额")
ax1.set_ylabel("人数")
ax1.text(0.5, 0.5, "绝大多数人\n挤在左边", transform=ax1.transAxes, fontsize=12, color='red')
# --- 图 2:双对数坐标下的分布 (Log-Log Plot) ---
# 这是数学家看到的“规律世界”:一条直线
# 我们不直接画 hist,而是画“互补累积分布函数 (CCDF)”
# 因为 hist 在双对数下噪音太大,CCDF 才是验证幂律的标准方法
# 1. 对数据排序
sorted_wealth = np.sort(wealth)
# 2. 计算排名比例 (y 轴)
# y = 1.0 意味着是第 1 名(最穷),y -> 0 意味着是最后一名(最富)
# 这里计算的是 P(X >= x),即有多少比例的人财富大于 x
y_vals = 1.0 - np.arange(len(sorted_wealth)) / len(sorted_wealth)
ax2.loglog(sorted_wealth, y_vals, marker='.', linestyle='none', color='#e74c3c', alpha=0.3)
ax2.set_title("图 2:上帝视角(双对数坐标)")
ax2.set_xlabel("财富金额 (对数刻度)")
ax2.set_ylabel("财富大于该金额的人数比例 (对数刻度)")
# 画一条辅助线,说明如果是完美的幂律,应该长什么样
# 幂律公式:P(x) ~ x^(-alpha)
# 在双对数图上,y = -alpha * x + b,即一条斜率为负的直线
ax2.text(0.6, 0.6, "近似一条直线\n证明了幂律的存在", transform=ax2.transAxes, fontsize=12, color='black')
print("绘图完成。请观察弹出的窗口。")
print(f"最高财富: {np.max(wealth):.2f}")
print(f"前 1% 的人掌握了 {np.sum(np.sort(wealth)[-int(NUM_PEOPLE*0.01):]) / np.sum(wealth) * 100:.2f}% 的总财富")
plt.tight_layout()
plt.show()
if __name__ == "__main__":
final_wealth = run_simulation()
plot_results(final_wealth)