


教大家个诀窍,如何让计算机容易犯错?
很简单。
超频。
如果不超频,这数亿晶体管工作超级稳定,没有什么犯错的机会。
本质上因为数字电路有着极高的“噪声容限”。
noise margin。
这种特性可以过滤掉所有的物理偏差。
我们日常生活中大部分的物理机械,它们的性能损耗都是连续的。
一个旧的机械秤,刻度会越来越不准;
一把旧的尺子,边角会磨损;
一个老化的温度计,读数会偏离一点点。
这就是模拟计算的本质 。
在早期的模拟计算机里,数字是用连续变化的物理量(比如电压、齿轮转动角度)来表示的,任何一点物理磨损、电气干扰都会导致一个微小的误差(比如计算尺或者模拟计算机)。

更要命的是,这些误差会像滚雪球一样,在每一个计算步骤中不断累积,最终让结果变得面目全非 。
而数字计算机的诞生,是对这种“连续性”的彻底反叛。
它做了一个最朴素、也是最颠覆性的决定:把整个世界简化成 0 和 1 两种离散状态 。
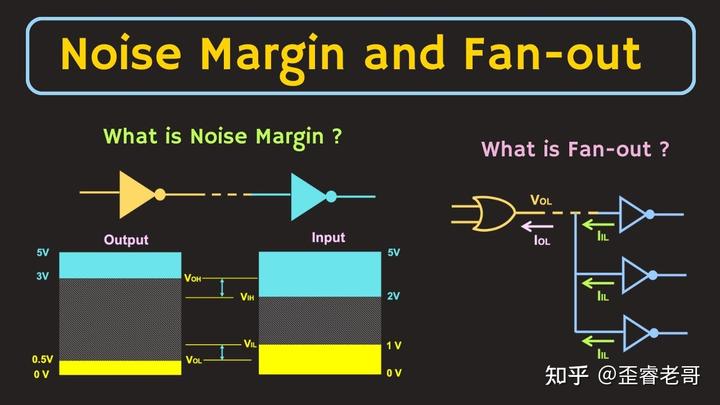
这就是门限电平:
对噪声不敏感。
对于别人给自己的输入:宽以待人
例如一个门电路只要输入在 2V 以上,它就一律当成“1”来处理 。
这个门电路只要输入在 1V 一下,它一律当成“0”来处理器。
这是数字电路的 Vih 和 Vil(学过数字电路同学更熟悉一些)。
这要给自己的电平凑合,就能识别出 0 或者 1。
但是数字电路又非常严于律己。
虽然对于输入要求不严格,但是输出却相对严格。
输出的“1”Voh 在 3V-5V;
输出的“0”在 Vol 在 0V-0.5V;
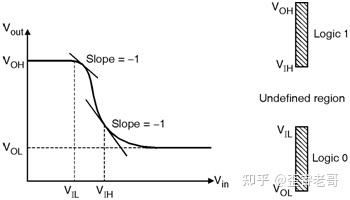
输出的范围永远落到输入的范围之中。
也就是所谓的 噪声容限(noise margin)。
这是数字电路的特性
这就好比你给一个小孩布置作业,只要求他把字写在方格里。
只要字不写出格,写得歪一点、斜一点都无所谓。
这使得电脑能够傲慢地忽略掉所有微小的物理损耗和电磁干扰 。
这种离散的 0 和 1 设计,从根本上杜绝了模拟计算中“误差累积”的问题 。
在模拟电路中,一个 0.1%的误差在经过 100 步运算后,可能变成 10%的巨大错误。
但在数字电路中,只要你那台快要报废的电脑还没有破旧到把“1”的电压拉低到“0”的门限以下,它的计算结果就永远是完美的。
而这样的场景基本不会出现。
可能有同学会问?
芯片里有亿万个晶体管在工作,如何保证它们不会乱套?
这就需要一个“总指挥”——时钟 。
所有的计算,都必须听从时钟的号令,在它发出的一个又一个脉冲信号下,同步进行。
为了确保计算的可靠性,芯片设计必须满足两个极其严格的时间要求:
建立时间(Setup time):数据必须在时钟信号到来之前就准备好,并且保持稳定。
保持时间(Hold time):时钟信号到来之后,数据还得再稳定一会儿。
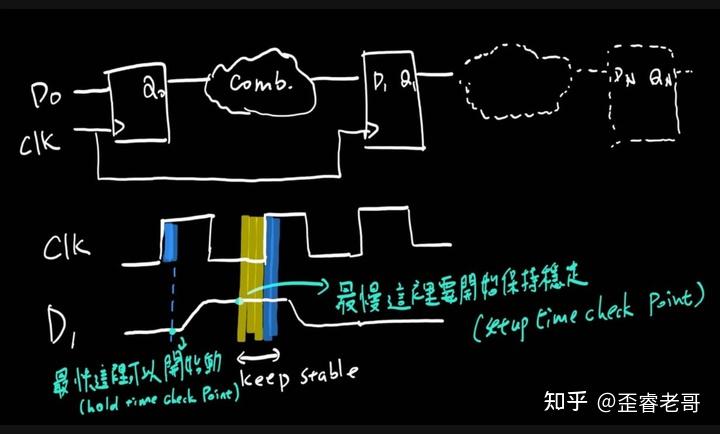
如果没满足这两个条件,电路就会进入一种“亚稳态”,产生不可预测的错误。
为了避免这种事发生,工程师们会刻意牺牲速度,把时钟频率定得比电路理论上最快速度要慢一些,从而给每个计算步骤留足时间 。
这就像一支乐队,每个乐手都必须在指挥棒落下时,以绝对精确的节奏演奏。
哪怕是为了迁就最慢的那个乐手,整支乐队也必须慢下来,因为跑调比慢半拍更致命。
所以,各位应该知道如何让计算机工作不稳定了。
那就是超频。
所以,手册的芯片的工作频率,已经考虑到了 setup 和 hold,还有时钟的 jitter 和 uncertainty。
能够非常稳定给数据采样留足了余量。
但是,超频带来的就是不稳定,(当然,也是稍微超频能工作的,这个就要看芯片的体质。)
你可能觉得,上面这些都说了,但万一还是出了错呢?
别担心,计算机早就想到了。
它在设计之初,就默认故障一定会发生,并为此留下了后手。
例如计算机的内存,因为 bit 多,在读写的就容易出错,可能悄无声息地翻转你内存里的一位数据 。
奇偶校验是一种较早的技术,它为每个字节(8 位)的数据增加一个奇偶校验位。
例如,如果采用偶校验,会将数据位加起来,如果结果是奇数,校验位就设为 1,使得总和为偶数。CPU 读取数据时会再次计算并与校验位比对。
uart(串口)就有这种奇偶校验的机制,。
计算机校验的机制很多(例如 CRC 等等),这里就不多说了,
校验可以“发现错误”,但由于无法确定具体是哪一位出错,它通常无法“纠正错误”
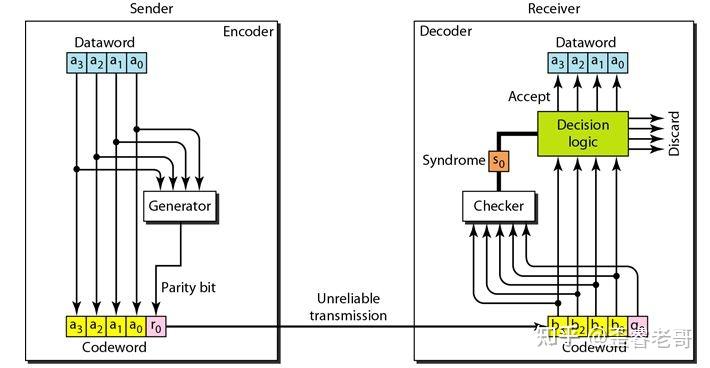
所以,ECC(Error-Correcting Code)技术就发明出来了,这个可以进行纠错。
DRAM 容易受到高能粒子辐射导致的翻转,导致读写错误,
1996 年,曾经有个 IBM 的研究说 256Mbyte,每个月错 1bit。
那么,ECC 内存可以自动检测并纠正这种单比特错误。

ECC 内存则是一种更高级的错误纠正技术。
它通过增加更多的校验位。
例如,对于 64 位数据,ECC 会增加 8 个校验位(实际上就是保留了更多的信息),可以自动“纠正”单个比特错误,甚至能“发现”双比特错误(需要更多的校验位)。
这使得系统即使在发生内存错误时也能继续正常操作,而不会因为错误而中断 。
那如果错误太严重,修不好了怎么办?
这时候,计算机就会执行它的“终极信仰”——蓝屏死机(或系统崩溃) 。
很多时候,内存坏了,机器就起不来了,自检内存报错,换根内存条就 OK 了。
但是,难道计算机就不会犯错吗?
当然会犯错。
1999 年,美国宇航局的火星气候探测器坠毁,原因仅仅是一位工程师忘记将英制单位转换成公制单位 。
阿丽亚娜 5 号火箭首飞自爆,是因为它重用了旧火箭的软件,结果 64 位的数字硬塞进 16 位的空间,直接溢出 。
计算机的机制再完美,也架不住人把代码写错。
所以,计算机最可怕的错误,不是硬件的,而是人的。