

 Founder of KALOS.art。设计师,漫画作者。
Founder of KALOS.art。设计师,漫画作者。
用 ControlNet 辅助引导插画创作
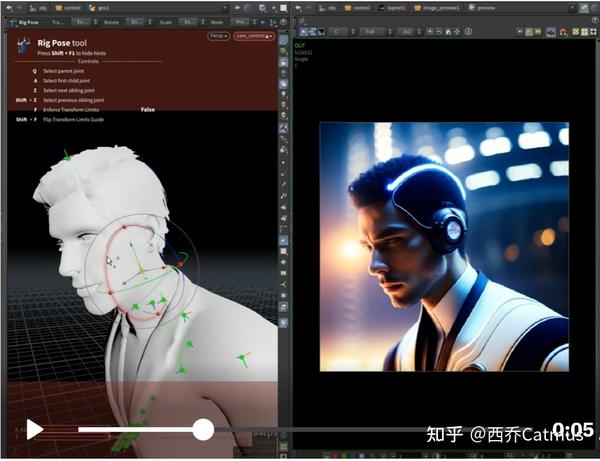
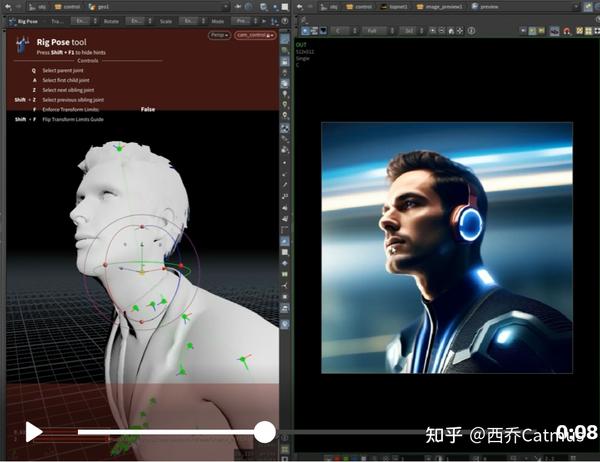
使用 Post reference 工具生成引导图像,精确控制生成人物的透视及动作。如果只使用 text prompt 引导,这是几乎完全无法做到的事。


另一个用 Post reference 工具(MagicPoser App) 生成引导图后, 使用 SD fine-tune 模型 Realistic Vision 完成的生成效果


使用 Control Net 里的 深度图引导 (depth map),精确控制透视和场景。


用 human post 引导,控制多人角色的生成
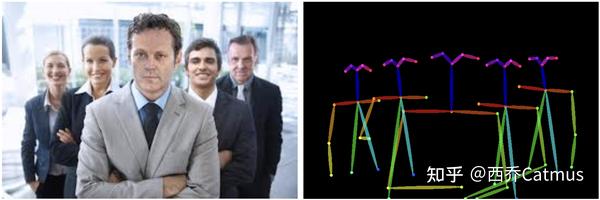

日本推友 @toyxyz3 做了一系列 post skeleton 引导的实验,非常有价值。
去掉 post skeleton 上的一部分肢体后引导,ControlNet 会引导生成时 将缺失的四肢处理为被遮挡,头部处理为侧面角度 (可能需要 prompt 辅助引导)。

改变 post skeleton 里是四肢的比例,ControlNet 会在引导生成时处理为透视角度。

改变 post skeleton 里的头身例,ControlNet 会在引导生成时将人物对象处理为不同年龄(或 Q 版)。

改变 post skeleton 里的肢体数量。。。ControlNet 会在引导生成时将处理为,额 ~ 半兽人。

@toyxyz3 还测试了更多人物数量。

多种条件引导的组合使用
虽然 Control Net 还不能原生支持多种 input condition, 但加上人工的后期处理,我们可以看见其应用潜力。
使用两种引导条件分别生成人物和场景
人物使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。分开引导效果更好,也让创作设计更为灵活。(人物合成前需要抠图。另外别忘了给人物添加投影)




同时使用不同引导图来覆盖满足两种控制需求
Reddit 用户 Ne_Nel 同时使用两张引导图(需要能支持两张 input image 的 SD 生成工具),一张用于ControlNet引导,一张上色后用于 img2img 引导,就可以同时控制生成结果的对象轮廓和颜色/光影。

这也是我非常期望拥有的一种引导方式,能同时从输入图像里读取边缘和颜色这两种引导条件。基于 ControlNet 和 T2I-Adapter 的框架,说不定我们很快能看到 这样一种新的引导模型被训练出来。
下面这个实验中,@toyxyz3 也试图实验 ControlNet 在 读取 Semantic Segmentation map 的 segments 时是否有可能带上深度或颜色信息 (并没有)
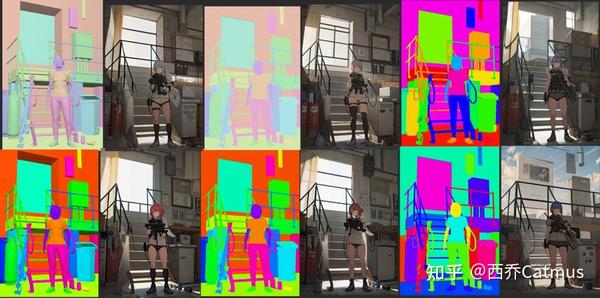
但第二天,社区就发现了 Semantic Segmentation的一个特质。Semantic Segmentation 语义分割是一种深度学习算法,名字里有“语义”一词是有含义的。这种算法将一个标签或类别与图像中的每个像素联系起来。被用来识别形成不同类别的像素集合。例如,常见应用于自动驾驶、医疗成像和工业检测。比如帮助自动驾驶汽车识别车辆、行人、交通标志、路面 等不同对象的特征。而每种标签都会有一个对应的标记颜色。
从 ControlNet 的论文中可知,它使用的 segmentation map model 用的是 ADE20K 的协议。 ADE20K 公开了它用于标注不同语义segments的颜色代码

这就意味着在设计 Segmentation map 引导图时,创作者可以反过来用。比如 改变某个 segment 的颜色,使之与 ADE20K 算法用于标注时的语义一致,比如 ADE20K 用于标注“钟表“的是草绿色,把背景那个形状块涂成草绿色,生成时,这个形状块就更大概率会被引导向生成显示器,其实该形状块与钟表常见的圆形形状不符。
不得不说,Stable Diffusion 玩家们的 Hacking 能力实在是强大。

下图和 Google Doc 里是 ADE20K 用于标注的颜色代码。

ControlNet 条件引导在3D和动画创作上的潜力
结合 Blender 使用 ContrelNet 创作 3D
Blender 里面创建的 3D 模型,导出静态图片作为 input image,使用 controlnet 的深度检测生产图像,再作为贴图贴回 blender 里的原模型上,bingo!虽然用于人体这类复杂曲面,效果会比较粗糙,但用于包装盒或建筑这类简单的几何体,应该会非常实用。
 https://www.zhihu.com/video/1611837025627324416https://twitter.com/TDS_95514874/status/1626331836459671552?s=20
https://www.zhihu.com/video/1611837025627324416https://twitter.com/TDS_95514874/status/1626331836459671552?s=20
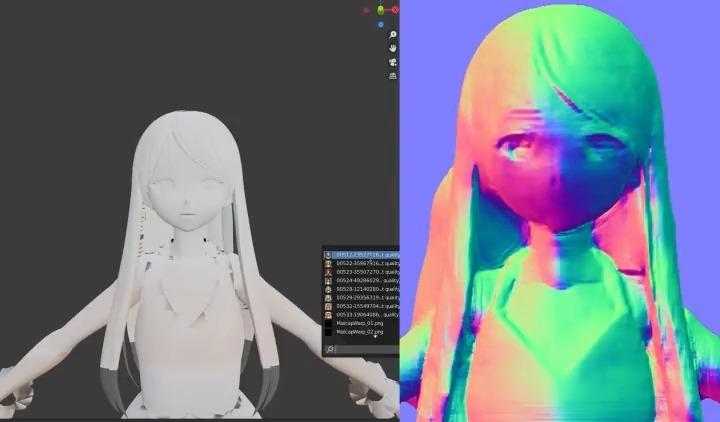
Use Controlnet's Normal mode to convert the 3D model into an illustration or anime style, then paste it as a texture on the original 3D model.
Normal mode reflects the detailed structure well, so you can texturing quite accurately.
结合 Blender 使用 ContrelNet 创作动画
在 Blender 里生成3D模型后,用不同颜色标记各个部位,再把动画序列导出后 在 ControlNet 里作为 Segmentation map condition 输入,生成的动画,各部件的结构有更好的稳定性和一致性,特别适用于身体部件之间有遮挡的动作。
 https://www.zhihu.com/video/1611837691120771072
https://www.zhihu.com/video/1611837691120771072
https://twitter.com/TDS_95514874/status/1626817468839911426?s=20
Rendering by color-coding materials for each part → If you use i2i with Segmentation of controlnet, the accuracy will increase considerably.
I think that it is effective especially in the part where the parts intersect and the subtle angle of the face.
使用两种输入引导的组合创作动画
人物动作使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。虽然还不是真正的 text to animation 生成,但这种方法已经能获得比之前都好的效果,更少的 glitch interference (跳帧感),人物动作更流程,背景也更稳定。
 https://www.zhihu.com/video/1611837949049249793
https://www.zhihu.com/video/1611837949049249793 https://www.zhihu.com/video/1611838002879279104
https://www.zhihu.com/video/1611838002879279104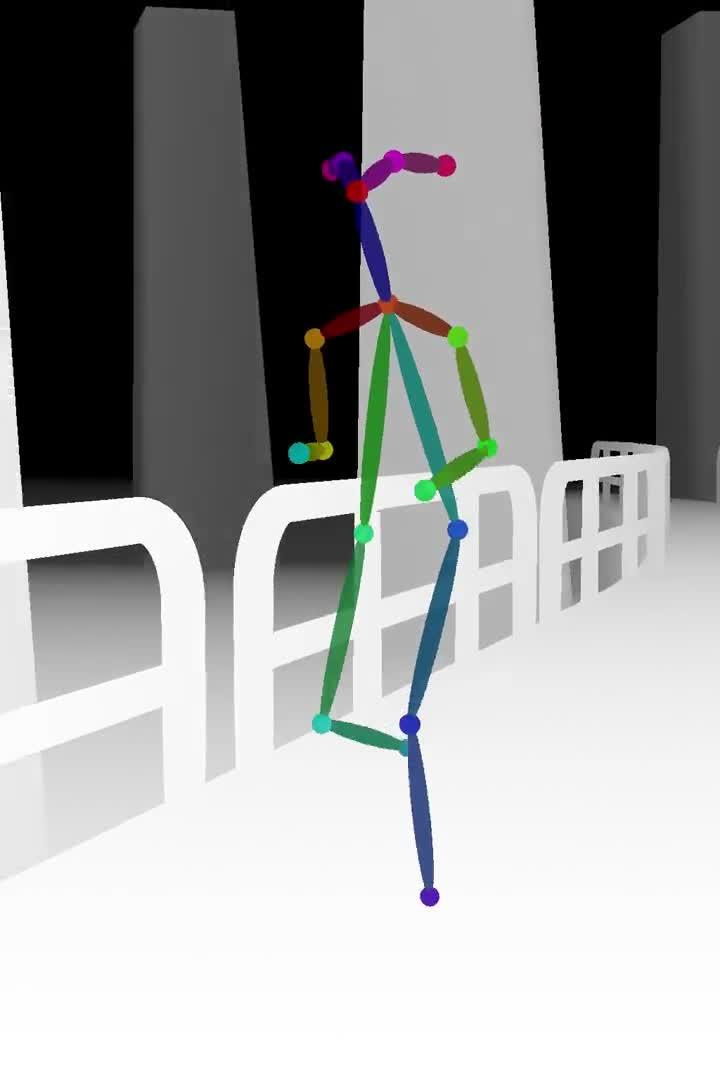 https://www.zhihu.com/video/1611838036945301504
https://www.zhihu.com/video/1611838036945301504
https://twitter.com/toyxyz3/status/1627417453734293504?s=20
哪里可以免安装且免费玩上 ControlNet 和 T2I-Adapter
集成到 Stable Diffusion WebUI 里
- 更新 WebUI 到最新版本, 在 https://github.com/Mikubill/sd-webui-controlnet 下载或安装,放到 WebUI 的 extensions文件夹内
- 在 https://huggingface.co/lllyasviel/ControlNet/tree/main/annotator/ckpts 下载文件放到插件目录下的annotator下的ckpts目录
- 在 https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main 下载模型(700M)或 https://huggingface.co/lllyasviel/ControlNet/tree/main/models (5.7G)放到插件目录下的 models 目录
可以预见,会有很多集成类似引导控制的插件、API、细分工具的爆发式出现, 比如

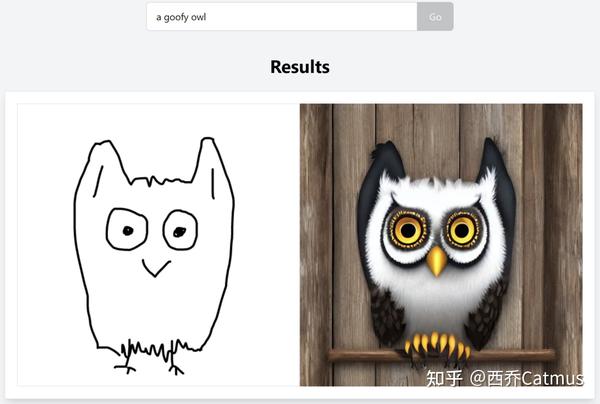
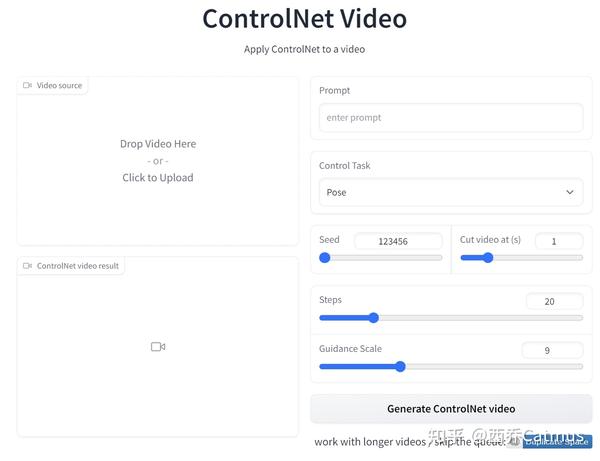
祝大家玩得愉快。
另外我刚刚发布了 AIGC 艺术家样式库 lib.KALOS.art 。一个 4 人小团队前后忙了 4 周。
- 目前全球规模最大,1300+ 艺术家共 3 万余张 4v1 样式图片
- 覆盖三个主流图像生成模型
- 为每个艺术家都生成了 8~11 种常见主题,如 人像、风景、科幻、街景、动物、花卉等主题

艺术家和多种主题的结合,会带来很多意想不到的结果。
后现代舞台设计师去画废土科幻场景?or 立体主义雕塑家去画一张猫咪?
按人类惯有思维,用肖像画家去生成肖像,用风景画家去生成风景,其实限制了AI模型的创作力和可能性。希望 lib.kalos.art 能帮你发掘 AIGC 的潜力,得到更多创作灵感。

