
因为项目的原因,最近半年小鱼一直在进行联邦学习方面的调研和研究。
题主关于联邦学习是否是伪需求的疑问,也是我一直以来的问题。因为我在这个领域还是萌新,所以仅分享一下看法,希望能抛砖引玉,和大家一起讨论。
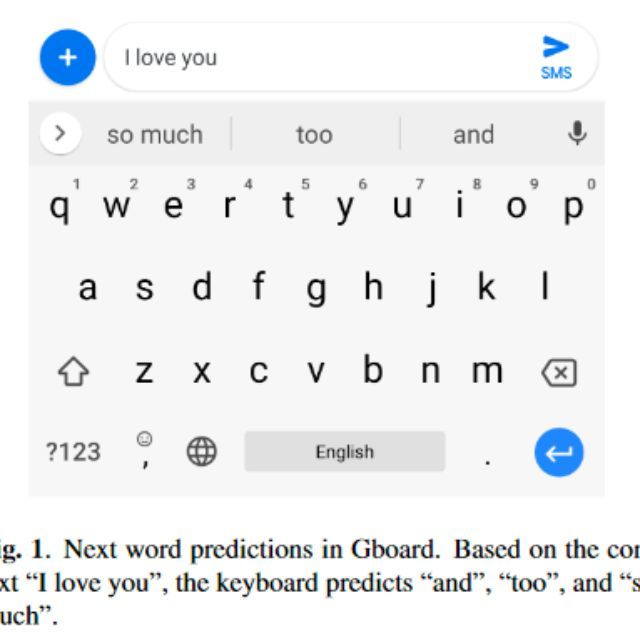
题主提到的“google 将手机上的数据拿来做机器学习”应该指的是联邦学习的开山之作[1],这篇文章我个人认为不仅首提了联邦学习的一个商业落地应用(隐私保护前提下,在用户的手机上训练模型,来进行输入法下一词预测的任务[2])。
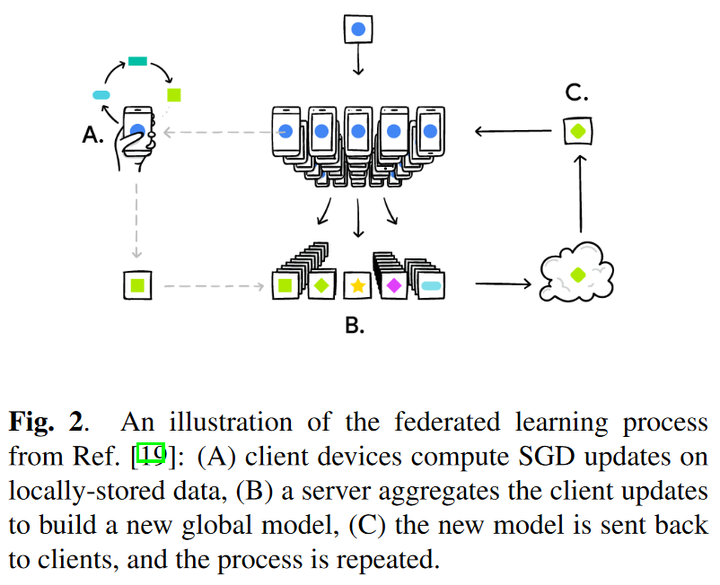
同时还明确指出了适用联邦学习的场景(当然后续几千篇的联邦学习论文大大拓展了适用场景,不过在此处先回顾一下谷歌这个工作的观点~)
联邦学习场景的数据应具有以下特性:
- 训练来自移动设备的真实数据比数据中心提供的代理数据具有明显的优势;
- 数据是隐私敏感的或较大规模的,不需要仅出于训练模型的目的将其记录在数据中心;
- 对于监督任务,可以从用户交互中自然地推断出数据的标签。
许多移动设备上的智能应用存在满足上述标准的数据
- 图像分类:预测哪些照片最有可能被分享出去
- 语言模型:用于改善语音识别性能或触摸屏键盘上的文字输入效果
它们同时满足上述三个特性:
- 数据是敏感的: 用户的照片或键盘输入的文本;
- 数据的分布也与代理数据提供的不同, 更有用户特点和优势;
- 数据的标签也是可以直接获得的:比如用户的照片和输入的文字等本身就是带标签的;照片可以通过用户的交互操作进行打标签(删除、分享、查看)。
同时,这两个任务都非常适合学习神经网络。

针对题主的问题逐条进行分析:
- “实际上将数据做好匿名化不就可以上传到服务器集中处理了吗”
我认为匿名化数据然后集中再训练模型确实是一种可行的方案。但现在因为 GDPR[3]等政策性的规定,共享数据是一种不被允许的不合规的行为。从这一点上来看,联邦学习并不是伪需求,而是一种适应隐私保护政策的(数据不出本地的)可行方案。
- 金融保险医疗机构自身的数据真的少到满足模型训练的需求(而且未来的增长也不会满足)吗?
各机构确实是不缺乏数据的,但肯定是缺乏“标注数据”的。对数据进行标注需要投入大量的人力物力,而有些领域需要邀请专家进行标注的代价更是高昂。
从标注数据的稀缺的角度去做事情的话,其实有很多思路,比如半监督学习 / 无监督学习,最近火热的自监督学习 / 小样本学习 / 零样本学习等研究领域,而联邦学习作为一种特殊的分布式机器学习方法,是有助于利用到更多地方的标注数据信息的。(同时联邦学习还提供了满足隐私保护,Non IID 数据需求的一些工具)
- 即使有更多的数据,当准确率达到一定程度后,边际效益也是递减的,且各个公司的数据分布、格式、完整性都千差万别,dirty work 不可避免,联邦学习带来的收益能覆盖这些成本吗?
因为小鱼我不在企业中,所以很难回答这个问题。我所知的是在互联网企业中,如果是关键业务,那么提升一两个百分点可能也是需要一个团队投入大半年的工作的。因为互联网平台受众广,哪怕提升很小,但也能影响到非常多的人。
我觉得这和另一个问题有些异曲同工之处:为什么互联网行业工资高?。当然如果提升性能的代价太大,我想企业也不会提出对应的 KPI 的…是不是可以将提升模型性能需要付出的精力和提升性能后带来的经济收益作为一个多目标优化问题去进行优化呢,我想这个可能是一个运筹学的问题了; )
而针对“数据分布、格式、完整性都千差万别”的现状,联邦学习中非常重要的研究领域就是Non IID 数据场景( @lokinko「联邦学习」— Non-IID 研究简介, @李新春联邦学习系列:NonIID 数据)。除了数据的异质性以外,甚至还有考虑系统、模型等异质性的研究工作[4]。
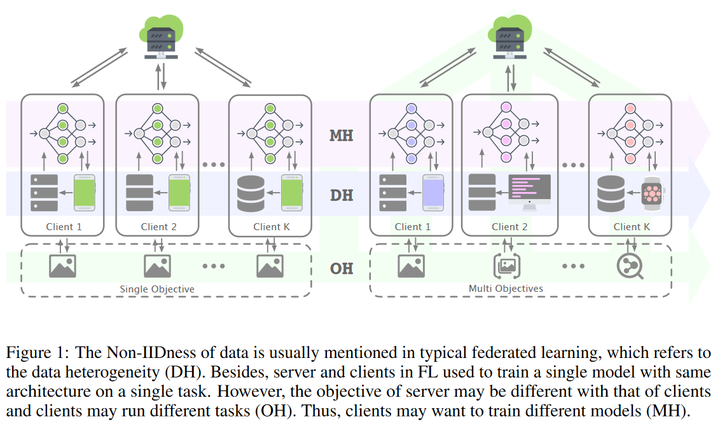
- 国内的一些成功商业案例有哪些?
联邦学习在业界的落地应用小鱼也一直在关注,先分享一份我认为还不错的资料[5]。(有更多更好的资料请都投喂给小鱼吧!)
中国信通院 - 联邦学习场景应用研究报告(2022 年)

如果要看学术前沿的落地应用的话,可以参考 NCS 等顶级期刊,我也做了总结[6],可以参考。

另外 @一般通过路人联邦学习是一个伪需求吗 提到很有现实价值的一个观点,我认为确实是联邦学习落地过程中的一个痛点,摘录如下:
我觉得目前来说落地最大的痛点,就拿横向联邦学习举例,公司要和用户 share 同一个 model,然后用户一起 train,上传 model parameter/gradient 给公司 aggregate。用户的隐私是被保护了,但公司的 model 呢?
换句话说,现在一个训练好的神经网络那么贵,哪个公司会愿意把自己动辄几千万美金训练的模型 share 给你一个普通用户?就算法律强制规定不得让用户上传原始的隐私数据,那公司也会更愿意选择其他的能保护住自己模型的方法,而不是我们现在看到的联邦学习。
所以现有的联邦学习从定义开始就是有问题的,忽略了对公司模型的保护,完美地体现了学术界和工业界的 gap。
这是一个很好的问题,我将其归类为针对模型的知识产权保护问题。据我所知这个还是一个较为前沿的领域,我也遇到了类似的问题,此前见到了三篇[7][8][9]很有意思的论文(比如 @可别当个键盘侠ICLR 2022 Oral: Non-Transferable Learning(反迁移学习)),同大家分享一下。
要是有相关的论文也请分享给我,可以一起研究一下~~
总的来说,我认为联邦学习是一套在特定场景下很有用的解决方案,它不能满足现实场景中模型训练和部署的所有需求,但确实提供了有参考价值的方法。如果将目光放更远一些,为了满足模型的可解释性、隐私保护、公平性、稳健性、泛化和迁移性能等需求可能涉及更大的领域,比如可信 AI(Trustworthy AI)。联邦学习是可信 AI 的重要一环~
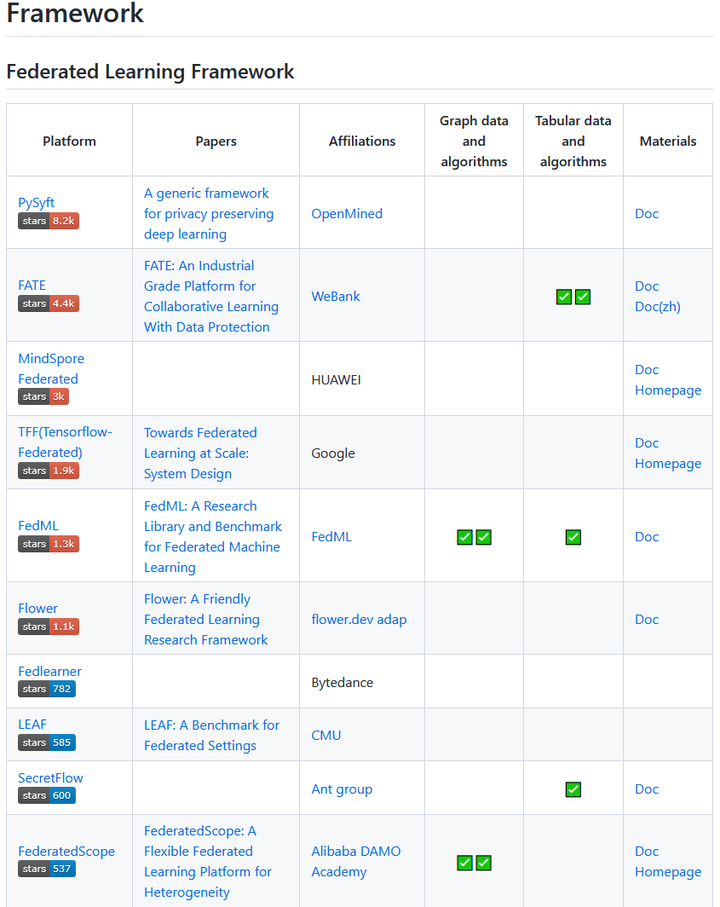
对啦,最后的最后安利一下小鱼的整理工作,小鱼维护了一个联邦学习领域的开源框架的清单(还整理了联邦学习在表格 / 图数据上的研究工作),如有需求可以点击查阅哦~