


技术发展超出了所有人的预期
最近做了很多关于 chatGPT 的研究,感叹技术发展之快。因为我在 2019 年前后接触过 NLP 的研究,当时身边的朋友普遍的论调都是“相比 CV 视觉领域,NLP 还需要 10 年才能应用”,现在看来真是目光短浅了。如今 4 年过去了,语言模型能处理的问题大大超出了我们的理解,落下 4 年的功课,最近重新研究,发现所谓的“大力出奇迹”不能完全概括 openAI 这群人在技术路径选择的远见和坚持。如果大家能细品这几年 NLP 领域技术发展之路,或许,会更感叹这群人的努力是多么珍贵。
本篇文章也是对我最近研究的一个总结。因为我从 2020 年开始已经再也没有写过代码,重新回看这些论文也很吃力,但是现在的思考角度会更偏向业务人员,所以我想,写出来的内容对于技术小白来说应该更好懂。
从循环神经网络 RNN 开始
我们把时间拉回到最早的语言模型身上。那时候最有效的模型应该就属 RNN,我们不去深究其中的细节原理,只从物理直觉角度阐述这一类模型的特点。
这一类模型主要是利用了语言中的前后次序关系来预测。“他好像一条狗”,“狗”这个词的预测依赖于之前的词,所以在模型的架构上,就是“循环结构”,下一个变量依赖于上一个变量。
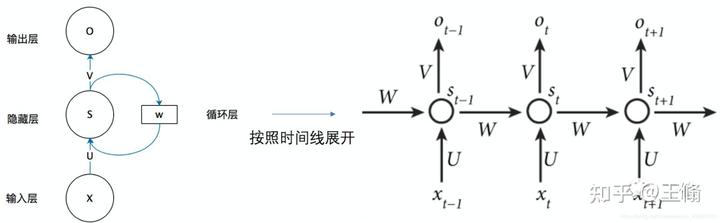
这一类模型在时序数据上面的表现很不错,时序数据不仅有语言,还包括了股票等数据集。这非常符合人类的直觉,但是也有不少问题:
第一,随着模型层数的增加,最早的数据会被淹没,词与词之间的关系无法被有效考量。
第二,无法并行计算,模型能够处理的数据量有限,由于模型中的次序关系存在,无法像图片一样用 GPU 并行计算,限制了模型大小。
第三,只能用在特定的学习任务上,比如说做翻译的模型,不能用来做文字生成。
一切的开始,Attention 和 Transformer
GPT 包括后续很多技术的开始其实都始于 google。2017 年,google 的研究员发表了一篇非常深远的文章,这也目前大多数语言模型的基石架构。
从直觉来理解其实非常简单。他们认为人类在说话的时候,每一个词和其他词有关联,就像人的注意力一样。我们看下面这张图更好理解,下图中输出的"it"和左侧的关系强弱可以通过颜色深浅看出来,那么这种机制可以被赋予权重从而应用在网络之中。
通过这样的注意力机制,语言模型就可以脱离开 RNN 结构,粗暴地甩开了之前大家常用的模型网络。算法的效果很不错,而且设计上非常精巧。
这里我想提一个很有趣的现象,笔者亲历,当时很多的科研人员尝试研究路径是将 Transformer 和 RNN 结合,效果确实也会变得更好,但是现在来看,这一个方向就是死胡同,所以回过头来看这段时间,会有不一样的体悟。
BERT 和 GPT-1,输在起跑线上
2018 年前后,openAI 开始发力了,他们发表了第一个 GPT 模型。同时代,google 也发表了 BERT 模型。下面是当时最火的三个模型。可惜的是,BERT 在很多问题上的表现优于 GPT-1。这也是为什么 google 没有发明 chatGPT,资本市场如此不认可的原因。
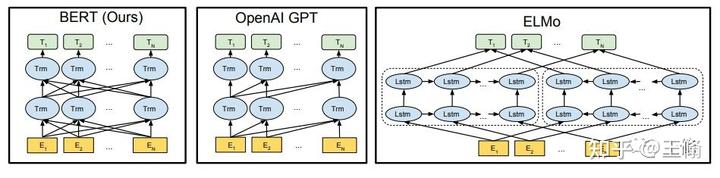
我们先说说 BERT 和 GPT-1 这两个模型到底比之前的好在哪儿,我觉得这也是 openAI 一群人搞明白技术路线的一年。
首先我们要知道传统的机器学习,你需要标注好的数据,比如说,我想要训练一个判断人类情绪的算法,我需要给机器数据,“input:我不开心,output:负面情绪”,这样的模型就有个巨大的问题,就是标准好的数据非常少,也很依赖人工,但是语言模型里面大多数数据都是没有被标注的,比如知乎上大部分的语料,都是没有 output 的,只有输入。如果纯依赖人工,大数据量是不能完成的。
这时候,BERT 和 GPT-1 提出一种思路,就是通过这些文字进行学习。BERT 是抓取一段话”他好像狗“,随机把其中的词遮挡住,”他[mask]像狗“,让模型去预测;而 GPT-1 则是把下一个词遮挡住,只给出上文让机器去预测,总而言之,这样就可以利用起网络上绝大多数的数据去训练模型。这一步就是他们的预训练过程。
在预训练结束之后,BERT 和 GPT-1 会在特定的任务下面进行进一步的训练达到更好的效果,比如会再用翻译的数据去训练一遍模型。有点像人先学拼音,而后再去写作文一样。
当然,BERT 和 GPT-1 还有模型结构的差异这里暂时不提。
这时候 GPT-1 的风头绝对不如 BERT,我记得我们当时学 NLP 的课程,老师特意让我们一起去读了 BERT,而 GPT-1 我当时都没怎么好好研究过。再加上 BERT 主要用于自然语言理解任务,如问题回答、文本分类、句子关系分析等,它可以理解文本中的语义和关系,并能够找出语句之间的联系,而 GPT 擅长的文本生成的场景,其余大厂都非常质疑,因为 AI 生成文本总是会胡言乱语。
GPT-2,坚持科研直觉
总结一下,目前的 GPT-1,只能用在特定场景,但是模型的框架、设计的思路,已经是一流的了。这时候 openAI 的团队提出一个非常有远见的科研直觉,他们认为语言模型应该处理多任务而不是单一任务。
举个例子,如果机器阅读过”2017 年 google 发表了 attention 机制相关的论文“,那么对于”attention 机制是由 google 在哪一年发表的“就应该能够回答,不需要再额外去做训练了(还记得吗,刚刚的 GPT-1 在预训练结束之后,还要 Q&A 的专项培训)。他们认为机器应该理解人类语言。
这就是科研人员的直觉和坚持了。我想这里面不仅仅是模型变得更深了,更多的是他们对于语言模型本质的思考,很多时候单纯的说别人”大力出奇迹“可能是心理安慰,忽略了他们在底层的思考。
回到我们的主题,GPT-2 的最大贡献是验证了通过海量数据和大量参数训练出来的模型,可以适用于多个不同的任务而不需要额外的训练。尽管对于某些问题,当时 GPT-2 的表现的甚至还不如随机回答,但是它在 7 个数据集中的表现,超过了当时最好的模型。值得一提的是,GPT-2 的模型结构本质上和 GPT-1 差别不是很大。
GPT-3,一骑绝尘的技术路线
随后的事情大家就知道了,有了这样的底层认知和经验,GPT-3 发表时,GPT-3 就是目前最强大的语言模型。除了几个常见的 NLP 任务,GPT-3 还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写 SQL 查询语句代码等。而这些强大能力的能力则依赖于 GPT-3 疯狂的 1750 亿的参数量, 45TB 的训练数据以及高达 1200 万美元的训练费用。
这里面不仅仅是所谓的”大力出奇迹“,这群科研工作者对于语言模型的本质思考可一点儿不少。不然,谁敢花这么多钱去训练呢。
GPT-3 的模型参数、训练数据和工作量都是惊人的,论文署名多达 31 个作者,所有实验做下来花费的时间和财力肯定是非常巨大的,即便是当时模型似乎还有 bug 和信息泄露的风险,openAI 也没有重新训练。
GPT-3.5 和 GPT-4,走向 closeAI
提个小八卦,大家去翻一下 GPT-4 的报告(他们把论文取名为:GPT-4 Technical Report)。99 页的论文啊,硬是一点技术细节都不讲,全是在秀肌肉。大家再看看这个参与人员名单,这才是人才和科技霸权最直观的体现。

结尾
我们当时那群研究过 NLP 的朋友们,还在这个领域搞研究的就剩一个人,这也是人才稀缺最直观的体现。
归根结底,很多时候风口不是追出来的,是人创造出来的,是真的喜欢、真的相信才会坚持。要是有人 5 年前跟我说,我要训练一个超大型的模型,然后可以处理所有的语言问题,从翻译到生成作文,我一定会觉得这个人脑子有问题,但是细细深究了 openAI 研究之路,我们会觉得一切也不是那么不可理解。
旁人难以理解的坚守背后,一定是非常人所及的认知高度。
所以说,技术发展或者说人类创新发展,它的功利心是很小的,那些很功利的下场,都不是很好,比如历史进程中的电子管小型化、GPU 的发展。找到内心所爱,持之以恒、不求回报、自由驰骋。