


字符编码,我愿称之为计算机历屎上的屎山王中王。
其支撑起了无数次谁都不服谁的争论。
几乎把所有主流操作系统都坑的不要不要的,并且至今仍然遗留着一大堆乱七八糟的问题。
并且最重要的是至今没有一个较为完美的解决方案。
我们先回到几十年前的某一天,作为一个根正苗红的阿美莉卡计算机攻城狮,你认为存储一个"字母",用几个 bit 合适?
已知我们有 26 个英文字母,我们算大小写翻个倍儿,加上数字标点,怎么的 128 种编码情况也够了吧,加上 1 个位作为拓展,一字节=8 位,简直特么的完美.

可以说 ASCII 字符集终结了 1byte=6 位,7 位,8 位,9 位这群魔乱舞的时代,但你别急,我们的故事才刚刚开始.
随着计算机的流行和发展,肯定不只有阿美莉卡在用啊,就说我们中文,<<汉语大字典>>收录的数量就有 5 万个,哪怕我们凑活凑活,只用常用汉字,那也有 3000 个左右,8bit 能表示的范围就 256 个,这显然不够啊

你会说,不要慌,8bit 不还给你留了一个扩展位么,我们可以这样,第一个字节如果高位是 1,那么后面那个就是扩展位,所以在 1980 年中国国家总局颁布了第一个中文编码 GB2312-80,不过这个编码的覆盖范围不够,所以后面又颁布了 GBK 编码,
简单来说如果第一个字节的范围是 0x81–0xFE,那么它就是一个汉字,你需要和第二个字节(范围 0x40–0xFE)去凑够整个汉字的编码.
很完美是不是?这是一个神奇的编码,具体怎么神奇我们稍候再说。
中文问题解决了,但是又有一个大问题,比如 90 年的后即十几二十年年,windows 是毫无疑问的操作系统一哥,没有之一,但显然 windows 不能只给我们中国用,它得挑一个别的编码,大到能够覆盖大部分国家的绝大多数语言。
这问题就大了,选啥好呢?
1991 年 Unicode 1.0 刚刚诞生,当时的 UCS-2(也就是后来的 UTF16)支持 65536 个码位,这就像 IPv4 地址被设计成 32 位被认为完全够用一样,当年他们也认为 UCS-2 足够覆盖所有的文字了。

那么,现在第一个问题来了,现在我们在网上聊天,在经过了一系列深入的交流后,我们决定对《金瓶梅》这部小说进行严肃的学术探讨,所以我把这本书的电子版 txt 发给了你。
那么它到底是 GBK 编码还是 UTF16 呢(UCS-2 后来的名称,后文为了方便我们都用 UTF16)。
然后我们都发现了一个问题,我们竟然无法通过 txt 这个文件的任何数据,知道它究竟是什么编码,所以,我们只能一个一个试过去,先用 UTF16 打开,哎呀,乱码,再用 GBK 格式打开,哦,正确显示了,所以它是 GBK 编码
但是,我们人还可以通过视觉手段判断一下到底是什么编码,但很多的文本处理程序可就要了老命了,因为文本的解析完全依赖编码,所以要么设置一个默认编码,要么让用户选一个。
要知道,很多的文员连键盘都用的不利索,你和他们说什么文本编码,那不为难我胖虎么?

现在,第一个坑还没解决,我们回到“GBK”是一个神奇的编码这个问题上来,为什么神奇呢,第一个它是非国际标准编码,所以 GBK 编码,几乎不具备通用性,特别像早期的 Linux 系统发行版,根本就不鸟你,但最关键的问题是,GBK 编码几乎没有纠错能力和快速索引能力
非常容易出现那种错了一个字节后面全错的情况(下面的程序故意误码 1 字节,导致后面的文本全错):
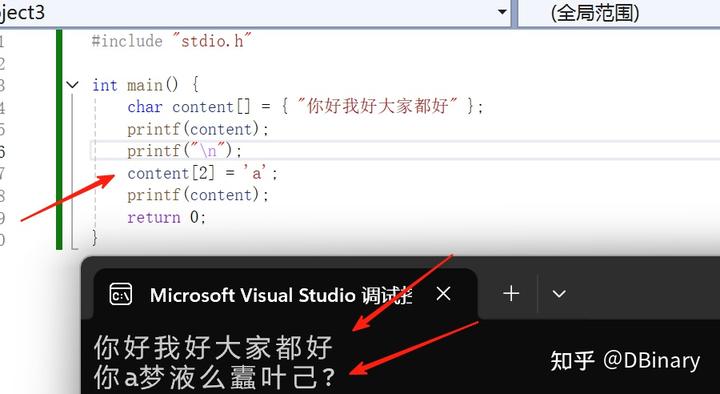
而快速索引指的是比如你要如何定位第 1000 个汉字呢,只要文本中有一个数字英文或半角标点什么的,你不得不从头解析整个字符串,就比如我们有一本长篇小说,我们想找到书里的第 100000 个汉字,我们不得不从头开始解析文本,这就导致了程序的文本处理效率极差。
更坑爹的是 GBK 编码第二个字节的高位不一定是 1,这就导致了其可能与 ASCII 码混叠在一起,假如你在写一个编译器需要非常小心的处理字符串编码,但某天你没有正确的识别(回到上面那个编码识别问题)代码编码,非常可能错误的把汉字的一个字节识别成 ASCII 字符,那你这个编译就直接炸了。
所以即使到今天,GBK 编码仍然是一个“非常难搞”的编码。
你是不是想说那我们不用不就得了,我们完全采用 Unicode 的几种编码。
别急,Windows 也后院起火了,今天我们知道了 UTF16,这特么完全就是一个神坑啊。
首先,UTF16 是一个多字节编码,那么问题来了,它到底是大端序还是小端序的呢?傻了吧,UTF16 这种编码内部还分家了,还直接拉上了另一个计算机科学里另一个“先有鸡还是先有蛋”的神坑问题里 ------ 到底是特么的大端好,还是小端好。
当然这不是什么事,真正坑爹的是,今天我们知道 UTF16 完全不够用,后来 Unicode 标准扩展到超过 100 万个码位。UTF16 为了兼容,发明了代理对这种神奇的玩意儿,这就导致了 UTF16 不再是定长编码而需要变长解析。
好家伙,合着 UTF16 是在统一编码快速索引一个问题都没解决,还在屎山上继续拉了一坨大的。
所以到今天,你可以看到 GBK 和 UTF16 在 windows 仍然坚挺,
属实是自己装的逼,再难受也得装下去。

但问题还是没有解决啊,要知道 Unicode 今天可不止一种编码,今天有 UTF8 UTF16 UTF32,其中多字节编码还有细分大小端(LE BE)问题。
兜兜转转,结果发现特么我们还是一个问题都没解决,一个文本文件过来,它到底是哪种编码。
这个时候微软又出来说,要不我们在文本文件最前面几个字节里标识一下这个文本文件到底用什么编码吧,这也就是我们今天说的 BOM 头
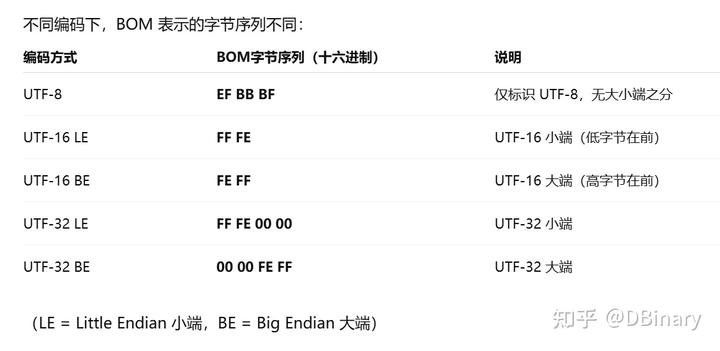
可惜,当时已经不是微软一家独大他说的算了,显然是上个逼他装的太失败了,比如 Linux Unix 和 GNU 一众表示,微软你特么就一个行业毒瘤,你说要支持就支持,那我不特么很没面子。

何况作为文本文件,前面还要塞一些东西进去,这会破坏 ASCII 特性,那这个文本文件还是文本文件么,那不成了四不像,不然你看我 HTTP 协议,说好的超文本传输协议,难不成也要加个 BOM 头,你丫的纯属脱裤子放屁,所以哪怕时至今日,BOM 头仍然在很多需要进行文本分析的软件和平台的支持受阻。
并且,即使 Unicode 编码的多种编码格式,与其说每种都解决了一些问题,不如说每种也都有严重的问题。
例如作为目前最广泛的 UTF8 现在各平台的支持度最好,但是仍然存在索引缓慢的问题,也就是之前说的你要定位某一个汉字,你需要从头开始解码整段文本,效率很低。而 UTF32 虽然能完美覆盖所有编码,但对于最常用的纯 ASCII 字符文本,虽然解决了动态索引速度问题,但其内存占用量直接翻了四倍。
所以目前主流的方案是,编码大多采用 UTF8 形式,解析完成后内存以 32 位 Unicode 形式存储。
除此之外,如何判断文本字符串结束,也常常打起来。
保守派认为文本以 0 结尾是一个优雅的实现。
激进派认为文本应该是抽象数据结构,应该在开头就标明文本长度(甚至编码)。
保守派认为,激进派这种设计结构会破坏数据的纯粹性,比如 C 语言中严格意义上只有以字符编码的数组而不是什么字符串结构,你加那么多莫名其妙的东西进去,那你说长度应该是几字节,到底用大端编码还是小端,如果长度数据也被破坏了咋办,char txt[]="abc",txt[0]到底是'a'还是什么别的神奇的东西?很多设计就是没事找事自己抽象把自己抽出事了.
激进派则认为保守派这种 0 结尾的方式造就了无数溢出安全问题,并且每次统计字符串长度都要从头扫描一遍,你不累么?你就是老登,看不得新登的好.
时至今日,这场屎山大战仍然在继续,至于有没有从失败中吸取经验教训.
反正至少目前为止,吸取了经验也没成功过.
额呵~
