


谢邀。CPU 会出错,而且一旦出错以后,会越来越频繁出错。出错还不是最可怕的,怕的是出错了你都不知道出错了,因为 CPU 里面有自动校正错误的机制。我们先脑洞一个场景:
某天,你坐在电脑前,与游戏中的怪物奋战时,一个神秘的宇宙射线到达地球。它逃过臭氧层的阻隔,穿过你的身体,击中电脑的内存条。你因为吸收了宇宙射线的能量变成了奥特曼,你的游戏人物属性也因为内存某个 bit 的翻转实力爆表,一刀把大 Boss 斩于马下。怎么样,就问你刺激不刺激?

也许变身只存在于好梦中,但硬件错误却时时刻刻在发生:一个电源的浪涌,电磁干扰和辐射等等都可能让电脑中的某些部分发生错误,而我们却很少看到这个错误:
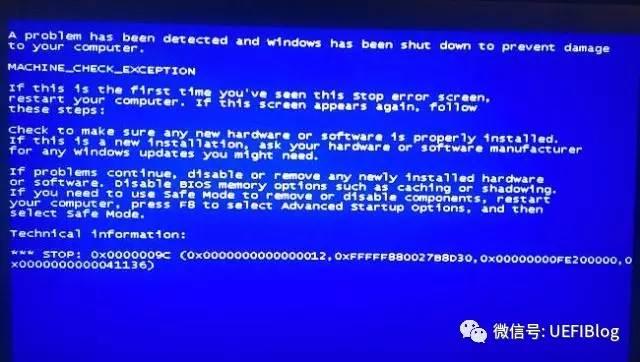
这是为什么呢?
其实硬件出错可以分为已被纠正的(Corrected)和不能纠正的(Uncorrected):
1. Corrected:硬件发生错误,但已经被硬件或者固件纠正,不需要操作系统做出动作。
2.Uncorrected: 硬件发生错误,不能被纠正。它又分为两种:Recoverable, 错误被限制在一定范围内,可以进行隔离恢复;Fatal,致命错误,除了重启别无他法。

硬件可以有很多种方法来纠正错误,本质上都是提供冗余。以 ECC 内存来举例,相对于奇偶校验位(Parity)技術,ECC 通过附加额外的 5 个比特可以发现 2 个 bit 错误或者纠正 1 个 bit 错误。内存的 Mirror 技术,利用双备份内存,发现并纠正出错的内容。如此种种,电脑硬件 / 固件利用各种冗余来发现和纠正错误。
那是不是纠正了就完了呢?实际上除非偶然的浪涌产生的错误,因为制造工艺、老化等产生的错误有愈演愈烈的趋势。这次的一位错误被纠正了,不加处理和重视,下次可能产生两位错误,那时就有可能从 Corrected 变成 Uncorrected!
Intel 的 CPU 利用 MCE 和 CMCI 来向操作系统报告错误;PCIe 子系统有标准的 AER 来报告错误;其他的硬件部分由 BIOS 通过 WHEA/APEI 来通知操作系统。下面我们重点来介绍 MCE/CMCI。
MCE/CMCI
Intel 从奔腾 4 开始的 CPU 中增加了一种机制,称为 MCA——Machine Check Architecture,它用来检测硬件(这里的 Machine 表示的就是硬件)错误,比如系统总线错误、ECC 错误等等。这套系统通过一定数量的 MSR(Model Specific Register)来实现,这些 MSR 分为两个部分,一部分用来进行设置,另一部分用来描述发生的硬件错误。
当 CPU 检测到不可纠正的 MCE(Machine Check Error)时,就会触发#MC(Machine Check Exception),通常操作系统会来处理#MC,它通过读取 MSR 来收集 MCE 的错误信息,并产生上面第一个蓝屏。当然由于发生的 MCE 可能是非常致命的,CPU 直接重启了,没有办法完成 MCE 处理函数;甚至有可能在 MCE 处理函数中又触发了不可纠正的 MCE,也会导致系统直接重启。
当然 CPU 还会检测到可纠正的 MCE,当可纠正的 MCE 数量超过一定的阈值时,会触发 CMCI(Corrected Machine Check Error Interrupt),此时软件可以捕捉到该中断并进行相应的处理。CMCI 是在 MCA 之后才加入的,算是对 MCA 的一个增强,在此之前软件只能通过轮询可纠正 MCE 相关的 MSR 才能实现相关的操作。
MC BANK
每个逻辑 CPU 实现了一整套错误属性、状态和控制寄存器。
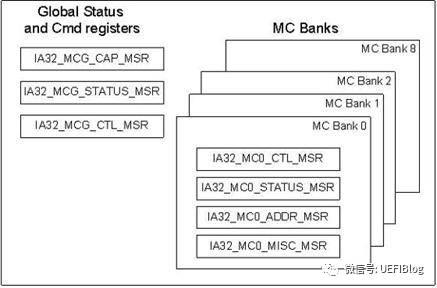
它分为左右两个部分,左边的是全局的寄存器,右边表示的是多组寄存器(Banks)。全局相关的寄存器组定义了如何开启 MCA 的能力。Bank 的数目由 IA32_MCG_CAP MSR 里面的 Count 来决定
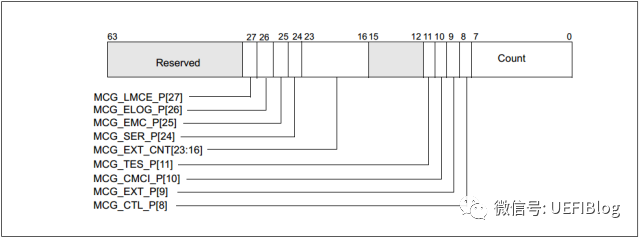
每一个 BANK 则具体对应一类错误源,如 CPU,MEMORY,CACHE,CHIPSET 等等。每一个 BANK 都可以进行单独的控制,这样软件就能够针对每一个 BANK 使用特定的方式进行处理。
随着越来越多的器件被整合进入 CPU,Bank 的数目也有越来越多的趋势,详细可以参阅芯片的 Spec。
CMCI
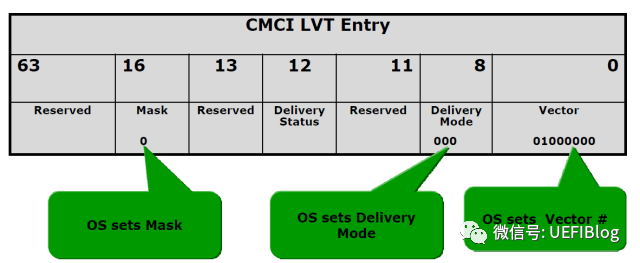
Corrected machine-check error interrupt (CMCI) 是在酷睿 CPU 时引入的新特性,叫做 eMCA。不同于原先需要操作系统来轮询(Polling)MC Bank 的方式,CMCI 提供了一种机制,当 corrected error 发生侧次数到达阀值的时候,就会发送一个信号给本地的 CPU 来通知系统软件。当然,系统软件可以通过 IA32_MCi_CTL2 MSRs 来控制该特性的开关。
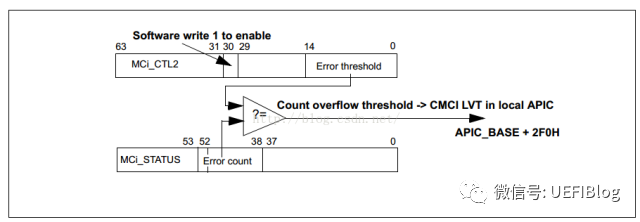
操作系统可以选择合适的 Error count 从而在问题严重了才让硬件报告,并在 CMCI 的 local APIC 的 LVT Entry 中填入合适的中断向量号码和模式等(计算机中断体系一:历史和原理 - 知乎专栏)
WHEA 和 APEI
看过了可纠正的错误,那么其他错误的处理呢?其实,更重要的问题是,可纠正和不可纠正错误发生了,不能简单的重启了事,错误的原因应该被记录和报告出来,便于管理员找出问题点。可纠正的错误我们可以记录在系统日志中,因为系统还可以使用。但是发生不可纠正的致命错误后,系统处于不稳定状态,谁来记录呢?这是个大问题。
因为服务器系统对可靠性的要求,微软很早就提出 Windows Hardware Error Architecture(WHEA),主要用于服务器操作系统 Windows Server 系列。它一改以往由 BIOS 和 BMC 对错误进行单独处理,OS 不知情的状态:
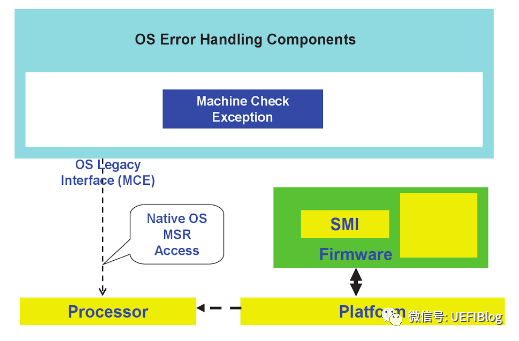
WHEA 通过扩展ACPI(ACPI 与 UEFI - 知乎专栏),加入了四个 table,用于固件向 OS 报告错误源,记录错误和注入错误,改进后的系统框图如下:
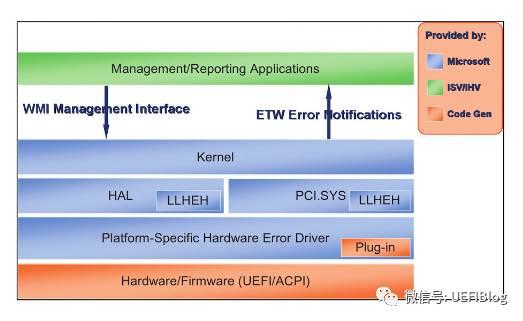
注意 PCI 和 CPU 都有自己的 LLHEH 来处理 MCE 和 AER。
由于 WHEA 的成功,ACPI 4.0 引入了它的几乎全部,只是给了个新的身份证(GUID)并起了个新的名字:APEI(ACPI Platform Error Interface)。毕竟 WHEA 里面的 Windows 并不合适作为工业标准的名字。
WHEA/APEI 十分复杂,我们单独撰文进行了介绍(WHEA 原理和架构)。
结论
硬件的纠错机制会让细微的偶然错误化于无形,看来依靠宇宙射线属性 +100000 的美梦并不现实。但同时也避免了数据的错误,帮助计算机系统健康稳定运行。也许我们可以打开 Windows 的系统日志看一下,你可能会发现计算机真是雷锋,做好事不留名!
最后推荐最新的 Intel NUC 小电脑,便宜又好用:
该文被整理发布在专栏:UEFI 和 BIOS 探秘。那里还有别的文章。欢迎大家关注 UEFI 专栏。
