


这个问题有两大误区(都源于大众的错误理解):1.大脑本身一直分泌多巴胺;2.快乐并不是多巴胺分泌的直接结果
展开讲:
多巴胺在大众意识中一直是作为一种跟动机[1][2]、欣快[3]关联的激素角色存在的,但它还有另一个身份:神经递质(Arvid Carlsson 研究确定了多巴胺作为神经递质的角色,这一发现使他赢得了 2000 年的诺贝尔医学奖)[4][5]。这个身份意味着它在大脑工作过程中扮演了不可或缺的信息传递者角色。也就是说,只要大脑在工作过程中,就会有多巴胺的分泌。最近技术的发展已经能够让我们实时的测量大脑中多巴胺的分泌情况[6][7],测量数据也证明了这一点[8]:
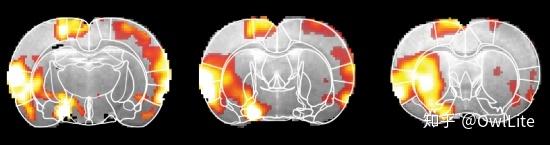
那么可以扩展一下这个问题,多巴胺的浓度可不可以无限上升而产生无限的效果呢,比如让人一直高兴?这个问题的答案也是显然否定的。无论是作为激素还是作为神经递质,多巴胺需要作用于多巴胺受体才能起效[9]。如果多巴胺受体都被绑定了,那么更多多巴胺的分泌并不会起作用。这也就是感知的动态范围问题。比如,一些毒品会比多巴胺更亲和多巴胺受体[10],能产生比大脑分泌多巴胺更强的效果。但是持续的吸毒不会无限度的增强欣快感,而且吸毒的效果会越来越差。
同时这也引出了第二个问题,即多巴按的奖赏结果(比如愉快)到底是如何产生的。这个问题在学术界已经被很好的解释,也就是Dopamine Reward Prediction Error Coding(预期奖赏误差编码)[11][12]. 这个理论简单又实用,已经作为人工智能中强化学习的基础假设被广泛使用了[13][14][15]。概括来说,多巴胺的效果并不是取决于其分泌的绝对数值,而是由“实际得到的奖赏(浓度) – 预期得到的奖赏(浓度)”这个差值来决定的。举个简单的例子,你回家路上捡到了 100 块钱,你当然会很高兴(实际 100,预期为 0),但如果有人告诉你在路上哪个地方有 100 块钱,你捡到了就不会这么高兴了(实际 100,预期 x, 0<x<100). 这个理论也很好的解释了同样事情导致的奖赏效果的削减,比如第一次谈恋爱往往山盟海誓,但第二次谈的时候不免相对少些热情,因为预期值升高了。这个现象也很像神经网络训练中的梯度。如果训练到某个步骤梯度消失了[16][17],就不会产生积极的反馈(反向传输),从而不会对网络优化产生效果,网络的性能也不会继续提升[18]。而神经网络梯度消失问题的基本解决花费了近一代科研人员的努力,这一问题的基本解决直接催生了深度学习。
综上,多巴胺虽好,外源性的扰动往往不会产生积极的效果。劝各位少打它的心思,实实在在地做事远胜于这些“捷径”。