


其他答案里提到的定义是一种比较“偷懒”的简单化,实际上所谓黏着、屈折、孤立语都没有非常好用的准确的定义。而且全球语言逾 7000,仅仅用三四个标签就像囊括所有多样性和普遍性显然不现实,所以当代类型学家将类型学研究推进到了“分布类型学”阶段。下面我们就详细了解一下,分布类型学的思想到底是什么样的。
1. 怎样的类型学?
给语言贴标签分类是类型学老古董,当代类型学研究早已经进入到了分布类型学 distributional typology,或者叫做 property-driven typology 的阶段。什么意思呢?也就是类型学的研究重心从“综合而言,这个语言是什么类别的?”转移到了“这个类型学特征有哪些取值?这些取值呈现怎样的分布?和哪些别的特征更容易共现?”因为前者很容易就漏分析许许多多具体语言的非典型处。那少量四五个标签完全无法描述的细节被发现海量存在[1][2]。而这些独立于语言的特征也不一定完全体现在某个特定的语言的方方面面。特定的语言完全可以从很多特征中取具体值然后杂糅在一起(比如很有名的汉语的必要成分都是 head-complement 语序,而非必要成分则全都是 modifier-head 语序的[3],又比如语言既可以同时具备声调和重音,也可以声调和重音一个都没有。参见我这个关于词韵律类型学的回答)。所以以下我们探讨的特征和特征值完全可以仅体现在某个语言的某个特定的结构中,而在另外的结构中又取了这个特征的另外的值。特征是 construction-specific 而不是 language-specific 的。
我们从这个角度来看看世界语言结构地图集 (World Atlas of Language Structure, 简称 WALS) 是怎样描述传统类型学标签,分析,黏着,综合和复综语的。WALS 将句法范畴和形态的对应关系分拆成了三个维度:融合度 (fusion),阶 (exponence),灵活性 (flexivity)。
2. 类型学指标2.1. 融合度[4]
融合度是指,句法标记或"构型 (formative)"和宿主直接在语音上的可辨析有多高的问题,是否词干和词缀的语音和音系上的线性界限清晰可见。第一类是孤立式构型 (isolating formative)。
(1) Boumaa Fijian (Dixon 1988: 53)
Au aa soli-a a=niu vei ira.
1SG PST give-TR ART=coconut to 3PL
‘I gave the coconut to them.’
过去时构型 aa 是一个独立的语音形式,不附着于任何别的词上。出现在任何环境都是 aa,不会因为前后的词的语音形式不同而改变形式。
第二类是连缀式构型 (concatenative formative),指那些必须附着在另外一个词上,语音上不独立的构型。
2) Turkish
git-ti ‘go-past’
yap-tı ‘do-past’
gel-di ‘come-past’
过去时的构型的具体语音形式取决于词干的语音特征。
第三种是非线性构型 (nonlinear formative)。这是指比如亚非语系那样的 template morphology,没办法从线性排列上分离出一个构型的类型。非线性直接修改其宿主的语音音系形态而其本身没有单独的表现。
(2) Modern Hebrew (Orin Gensler, p.c.)
a. šamar-ti
guard.PST-1SG.PST
‘I guarded’
b. ʔe-šmor
1sg.FUT-guard.FUT
‘I will guard’
可以看到在希伯来语中时态的构型直接和词干融合在了一起,无法像连缀和孤立式构型那样分离出一个相对独立的语音单位。另外一种非线性构型是语法调。
(3) Kisi (Childs 1995: 220-3)
a. Ò cìmbù.
3SG leave.PRES.HABITUAL
‘She (usually) leaves.’
b. Ò cìmbú.
3SG leave.PST.PFV
‘She left.’
习惯标记表现为在词末音节上的低调,而过去时则体现为高调。这几种特征在一个 165 个语言的采样中呈现以下分布:
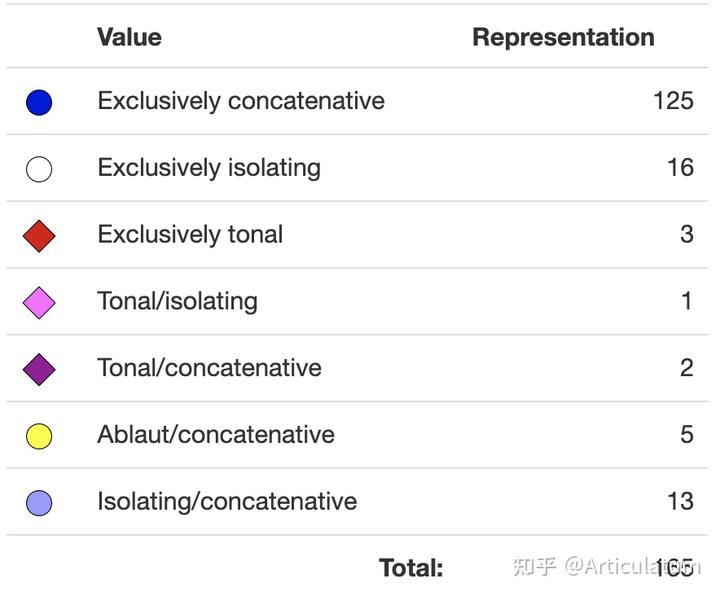
可以看到绝大多数语言都使用连缀式构型来标记语法范畴。
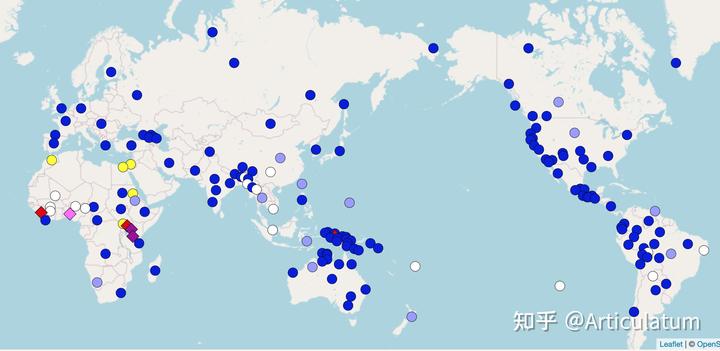
汉语属于同时有独立型 (各种声调独立的介词) 和连缀式(了等轻声虚词)的。日韩语和大部分印欧语都是只有连缀式的。其他的非线性(声调和元音内曲折)则主要分布在分洲大陆和阿拉伯半岛。
2.2. 阶[5]
阶 (exponence) 指的是一个构型中体现了多少个不同的语法功能范畴。很直观地,我们可以把构型分为单阶 (monoexponential) 构型和多阶 (polyexponential) 构型。多阶构型一个很典型的例子就是印欧语中的性数格,很多印欧语里性数格都是两两绑定甚至三个绑定在一起体现在一个构型上的。而像典型地传统视为黏着语的土耳其语和日语就基本上只使用单阶构型。比如刚才看到的土耳其语过去时构型就是单阶连缀式构型。
(1) Wari’ (Everett and Kern 1997: 339)
Toc na com.
drink.SG 3SG.REAL.NONFUT.ACTIVE water
‘He is drinking water.’
Wari'中的 na 表示第三人称,单数,事实,非未来和动作五个语法范畴,然而在语音形式上它又不附着于任何一个宿主词,所以这个 na 是一个多阶孤立式构型。

上图显示的是格标记的情况。可见,采样中的大部分语言都单独标记格。少量的语言将格与数,指称或时 - 体 - 态等范畴一起标记在一个构型上。俄语就是格和数范畴融合了的例子。俄语单数属格式 -i 或者 -a,而复数属格是 -ej, -ov, 或者 -ø (零标记)。格与指示融合的例子来自塔加洛语 (Tagalog, 菲律宾)。当 ang 改变标记的论元时,动词的形态也会相应随之变化。塔加洛语里这个 ang 并不是话题或焦点标记是因为,它在句中是必要成分,必须有至少一个论元携带了 ang 标记。而不像别的有专门的话题和焦点标记的语言那样,是选择性出现的。
a. Bumili ang=lalake ng=isda sa=tindahan.
PFV.A.buy NOM=man GEN=fish DAT=store.
‘The man bought fish at the store.’
b. Binili ng=lalake ang=isda sa=tindahan.
PVF.P.buy GEN=man NOM=fish DAT=store
‘The man bought the fish at the store.’
c. Binilhan ng=lalake ng=isda ang=tindahan.
PDF.D.buy GEN=man GEN=fish NOM=store
‘The man bought the fish at the store.’
格与时 - 体 - 态的例子可以看 Kayardild (Tangkic; Queensland, Australia),-y 和 -wu 一个标记现实中的论元,一个标记未来时空中的论元。
a. Ngada kurri-nangku mala-y.
1SG.NOM see-NEG.POTENTIAL sea-LOC.ACTUAL
‘I could not see the sea.’
b. Ngada kurri-nangku mala-wu.
1SG.NOM see-NEG.POTENTIAL sea-PROPRIETIVE.FUT
‘I won’t (be able to) see the sea.’
2.3. 灵活性[6]
灵活性是指同一个语法功能范畴能用多少个不同的构型表达出来。比如英语中的所有格,既可以 用 N's 标记,也可以用 of N 的形式表示。
(2) Warndarang (Australia: Heath 1980b: 28-29)
a. ng-baba
1-father
‘my father’, ‘our father’
b. wu-radburru ngini
NCM-country 1SG.GEN
‘my country’
Warndarang 中亲属关系的领属关系,和一般名词的领属关系需要用完全不一样的所有格构型表达。WALS 提到的领属关系的 allomorph 最复杂的是 Anêm 语 (巴布亚新几内亚),有多达 20 种表达领属的不同构型。见下例:
| water | child | leg | mat | |
|---|---|---|---|---|
| 1SG | kom-i | gi-ng-e | ti-g-a | mîk-d-at |
| 2SG | kom-î | gi-ng-ê | ti-g-îr | mîk-d-ir |
| 3SG.M | kom-u | gi-ng-o | ti-g-î | mîk-d-it |
| 3SG.F | kom-îm | gi-ng-êm | ti-g-î | mîk-d-it |

3. 结语
类型学核心要义自从五六十年代当代类型学先驱 Greenberg 以后发生了巨大的变化。比如语序类型学就已经从单纯的排列 S, V, O 演进到了将 S 和 V 的顺序与 V 和 O 的顺序分开来看[7][8]。在我看来传统标签式类型学就像星相学,总共就那么几个标签,要描述 70 亿人的复杂性格和心理类型,而且还要给每个人下一个定论,实在是有点勉为其难。传统形态句法类型学总共四五个标签,要描述全球数千个语言,不是也有点捉襟见肘吗?但是我们先定义可能的变量和变量类型,然后看这些变量在一个个具体的句型中是如何存在的,是不是感觉就科学多了?而且还更方便做特征间的联动研究。
所以类型学上所谓分析,综合,黏着,复综的分类也可以被打上“语言学中哪些概念并不科学?”的标签才对。