


结论:
简单说就是"嘉祺"这个 token 在模型的概率分布里出了问题。通过实验可以看到,即使在强力指令诱导下,"嘉祺"的生成概率始终低于 0.05,远低于正常水平。更关键的是,当用一个概率更低的"责"字测试时,模型反而能成功生成"马责",说明不是训练数据不足的问题。最终推测可能是该 token 在语义空间中与其他高频词高度相似,导致模型容易被"带偏",或者在训练过程中其概率被异常抑制。
下面是
猜想一:tokenizer 有问题
首先我们用 minimax 的 tokenizer 来解码这个词

可以发现 tokenizer 工作正常,“马嘉祺”会被拆分成“马”和“嘉祺”两个 token,猜想一不攻自破
猜想二:“马嘉祺”训练不充分
接下来就要验证为何模型无法生成“马嘉祺”这个词组了
我们用 instruction following 来让模型根据“马”来生成“嘉祺”
方案一:few-shot learning

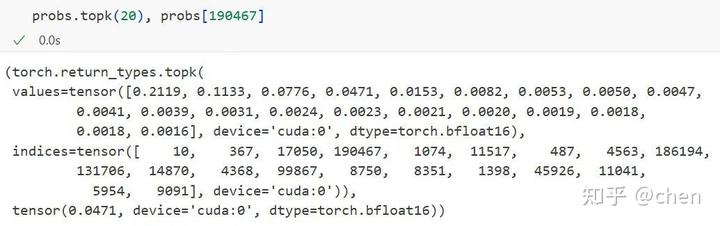
方案二:instruction+repeat


可以看到,在两个方案中,“嘉祺”这个 token 的概率始终<0.05,如果加上 temperature,这个概率只会无限接近 0,自然是无法采样出来的
这个现象可以解释“训练不充分”的猜想吗?事实上正相反,“训练不充分”只能解释模型在正常采样的过程中无法输出“马嘉祺”这个词组,而 instruction following 是可以让模型生成自己没见过的词组的
可是在我如此强力的 instruction 诱导之下,模型依然无法生成“马嘉祺”这个词,说明实际上不是训练不充分的问题
为了验证这一点,我们使用下面这个 prompt,让模型以“马”为开头组人名

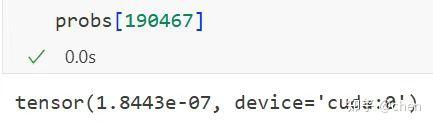
可以看到“嘉祺”的概率非常小,只有小数点后七个位
如果我再找一个概率比“嘉祺”还小的 token,但是模型能够通过 instruction 生成“马”+ 这个 token 的组合,就代表验证成功了
于是我们随机找到一个字“责”,这个字生成的概率比“嘉祺”还要低一个量级,用它来重新跑我们之前的 prompt
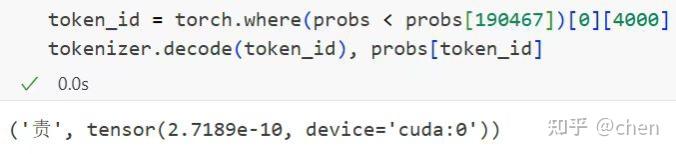

可以看到,“马责”被成功生成了,说明不是“马嘉祺”这个词组训练不充分的问题
只剩下一种解释,P(“嘉祺”)本身出了问题
猜想三:P(“嘉祺”)的概率出了问题
首先我们做个前置实验,让模型来解释“嘉祺”这个词

可以看到,模型根本不认识“嘉祺”,“嘉祺”这个词,似乎不在模型的语义空间内
我们可以做一个简单的复现工作。在 m2.5 的 tokenizer 中,总共使用了 200053 个 token,而 m2.5 的 embedding 支持 200064 个 token,这剩下的 11 个 token 不存在于模型的语义空间内。我们可以尝试要求模型来生成其中之一

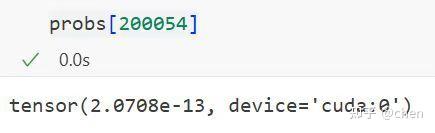
结果成功复现了模型无法生成“嘉祺”的现象。说明无法生成“嘉祺”的原因,正是“嘉祺”的概率出了问题
到此,模型为何无法生成“马嘉祺”已经破案了。但是导致这个的原因是什么?
我一开始有个假设,是在后训练阶段 RL 的过程中,惩罚了 P(“嘉祺”丨......),但这个假设有两个问题:
1. 按理说,RL 阶段的惩罚,只会降低一个词出现的概率,但模型的表现更像是压根不认识“嘉祺”,像我给它输入了一个它从未见过的 token
2. m2.5 的 base 模型没有开源,我无法验证或者推翻这个假设
似乎看起来问题出在预训练?为了验证是不是预训练阶段的问题,我想了一个方法来验证
有这么个结论:在高维空间中两个向量随机互相垂直。如果一个 token 在 embedding 初始化后就没怎么被训练过,那么它对应的 embedding,理论上应该和非常多的 token 都是垂直的
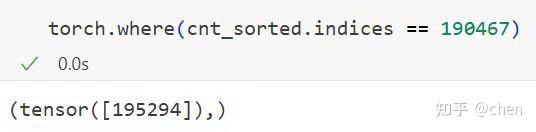
那么我只需要把 embedding 拿出来计算一个相似度,然后设个阈值来判断是否垂直,再看与“嘉祺”这个 token 相垂直的 token 数量在所有 token 中排多少就可以了(降序)
结果跟我预期完全相反,“嘉祺”不仅没有排在前面,相反,它排在了相当后面的位置
这让溯源又陷入了瓶颈...
吗?
我列出了在所有 token 中,垂直数量最多的前几个 token

可以看到 200054-200063 赫然列入其中,说明这个猜测是对的
然后,我从中找了两个很像样的 token 来测试,让模型解释这个 token
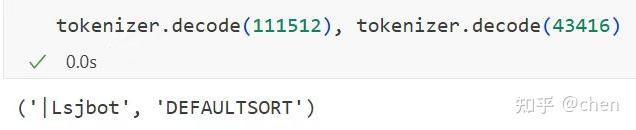


结果模型竟然表现出了和“嘉祺”极其类似的行为,它似乎根本不认识这个词
这个验证结果说明,未经充分训练的 token,确实会让模型出现看不懂的情况。用这种方法在 tokenizer 中去找词,很容易找到模型不认识,无法生成的词
但这似乎并不是“嘉祺”这个词无法正常生成的原因,要想确认“嘉祺”无法正常生成的原因,还是得依赖于 m2.5 base model 计算后训练前后概率发生的变化
最后再我大胆做个猜想:很可能模型无法正确识别“嘉祺”的原因在于,这个词虽然经过了一定训练,但是在模型的语义空间中,它与另外几个词有着极高的相似度,而这些词在模型的权重里占比更大,模型很容易偏离到这些词上,“嘉祺”就变成了“嘉诚”、“祺”。但我确实没时间继续验证这个猜想了,感兴趣的朋友可以试试